Transformer:从NLP到计算机视觉
发布时间:2024-09-19
Transformer模型最初在自然语言处理(NLP)领域取得巨大成功后,迅速扩展到了计算机视觉(CV)领域,并带来了革命性的变化。这种基于自注意力机制的深度学习模型,不仅在NLP任务中力压群雄,也成为CV领域的新宠。
Transformer模型在NLP领域的成功主要归功于其强大的建模全局上下文的能力和在大规模预训练下的可转移性。2017年,Vaswani等人首次提出Transformer模型,随后Devlin等人在2018年基于Transformer提出了BERT模型,在多种语言任务上达到了先进水平。此后,GPT系列、RoBERTa、T5等基于Transformer的模型不断涌现,展现出强大的性能。
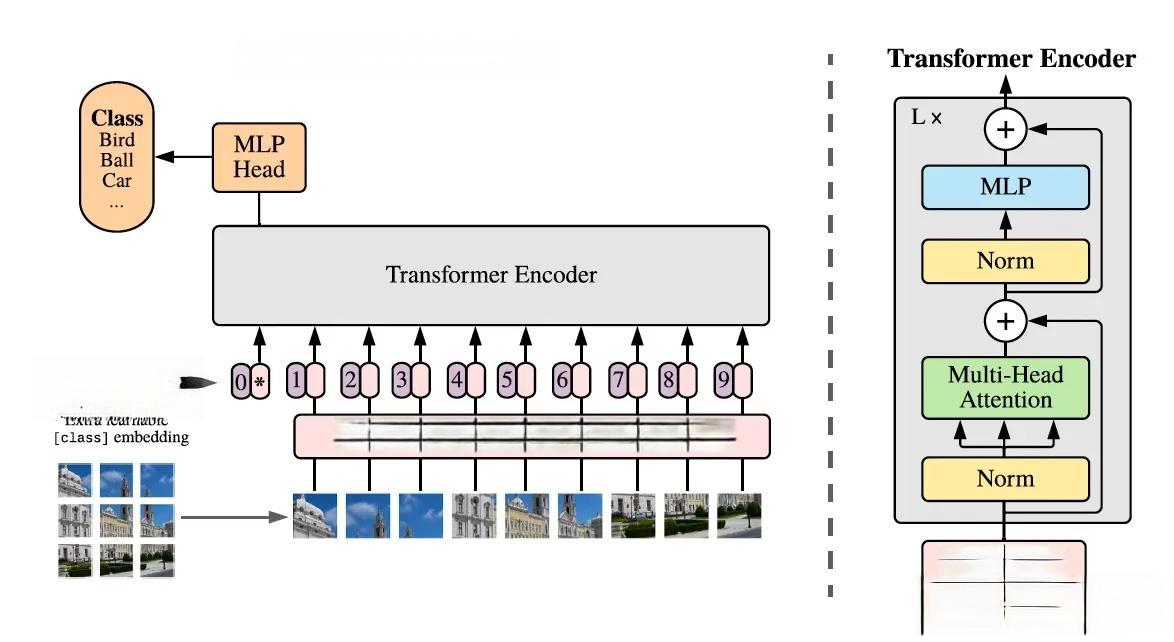
在CV领域,传统的卷积神经网络(CNN)虽然在许多任务上取得了显著成果,但其有限的感受野使其难以捕获全局上下文信息。受Transformer在NLP领域成功的启发,研究者们开始尝试将Transformer应用于CV任务中。2018年,Parmar等人提出了Image Transformer模型,用于图像生成任务。2020年,Carion等人基于Transformer提出了DETR(Detection Transformer),在目标检测任务上取得了与Faster-RCNN相当的性能。同年,Dosovitskiy等人提出了ViT(Vision Transformer),在图像分类任务上取得了88.55%的Top-1准确率,超越了ResNet系列模型。
Transformer在CV领域的应用远不止于此。除了图像分类和目标检测,Transformer还被应用于语义分割、图像处理和视频任务等多个领域。例如,SETR模型使用Transformer编码器替换基于堆叠卷积层的编码器进行特征提取,用于图像分割任务。ViT-FRCNN模型将ViT与FRCNN结合,用于大型目标检测任务。MVT(Masked Vision Transformer)用于野外的面部表情识别任务。
Transformer在CV领域的优势主要体现在其强大的全局上下文建模能力和灵活的结构。与CNN相比,Transformer能够更好地捕捉长距离依赖关系,这对于需要理解全局信息的CV任务尤为重要。此外,Transformer的结构更加灵活,可以适应不同尺度的输入,这对于处理不同分辨率的图像非常有利。
然而,Transformer在CV领域的应用也面临着一些挑战。首先是计算复杂度问题,原始的ViT模型计算量非常大,不利于处理高分辨率图像。为了解决这个问题,Swin Transformer提出了窗口注意力机制,将计算复杂度从token数量的平方关系降低到线性关系。其次是泛化性能问题,一些研究通过知识蒸馏等方法来提高Transformer的泛化能力。
展望未来,Transformer在CV领域的应用前景广阔。随着研究的深入,我们可能会看到更多创新的Transformer架构和应用。同时,Transformer与CNN的结合也可能带来新的突破。无论如何,Transformer无疑已经成为推动CV领域发展的关键力量之一。