多任务多模态的统一Transformer:向更通用的智能迈出了一步
发布时间:2024-09-03
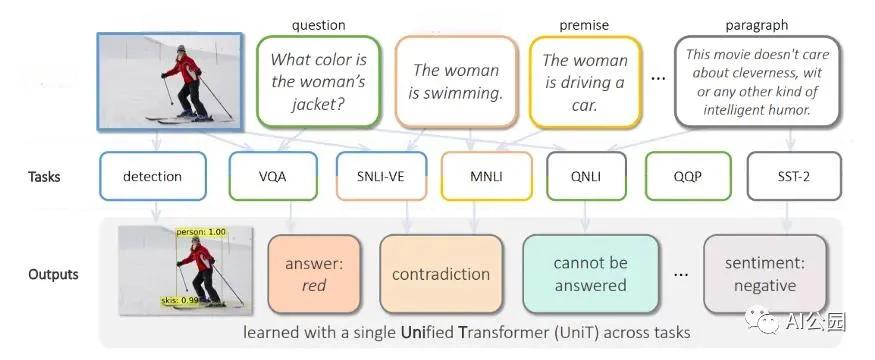
Transformer模型自2017年问世以来,彻底改变了自然语言处理领域。它通过自注意力机制,实现了对序列数据的高效并行处理,一举取代了传统的循环神经网络(RNN)。如今,Transformer不仅在NLP领域大放异彩,更在计算机视觉、音频处理等多个领域展现出强大的通用性。而多模态统一Transformer的出现,更是为AI向更通用的智能迈出了关键一步。
多模态统一Transformer的核心在于其统一的架构。它使用相同的参数集同时处理文本、图像、音频等多种模态的数据,实现了真正意义上的统一学习。这种设计不仅大大简化了模型结构,更重要的是提高了模型的泛化能力。传统上,处理不同模态的数据需要设计专门的模型和算法,这不仅增加了开发成本,也限制了模型的泛化能力。而多模态统一Transformer打破了这一局限,为实现更通用的智能铺平了道路。
Meta-Transformer框架是多模态统一Transformer领域的最新研究成果。它由香港中文大学与上海AI Lab联合开发,能够同时处理多达12种不同的模态数据。Meta-Transformer的核心组件包括数据到序列的标记器、模态共享编码器以及任务特定头部。其中,模态共享编码器使用冻结的参数来提取输入数据的高级语义特征,这意味着无论是文本、图像还是音频等模态的数据,都能通过这个编码器生成统一的表示。这种设计不仅简化了模型结构,还提高了模型的泛化能力。
多模态统一Transformer的应用场景非常广泛。在天气预测、卫星遥感、自动驾驶、智慧医疗等领域,它能够处理自然语言、图像、点云、音频等多种模态的数据,提供更加丰富和全面的信息支持。例如,在自动驾驶场景中,多模态统一Transformer可以同时处理来自摄像头、雷达、激光雷达等多种传感器的数据,为车辆提供更全面的环境感知能力。
然而,多模态统一Transformer的发展仍面临一些挑战。首先是计算资源的问题。处理多种模态的数据需要更大的模型和更多的计算资源,这可能会限制其在某些设备上的应用。其次是模态对齐的问题。不同模态的数据可能具有不同的时间和空间尺度,如何将它们有效地对齐是一个需要解决的技术难题。此外,如何设计有效的多模态损失函数,以平衡不同模态之间的学习,也是一个值得深入研究的问题。
尽管面临挑战,多模态统一Transformer的发展前景依然广阔。随着硬件技术的进步和算法的优化,我们有理由相信,多模态统一Transformer将成为推动AI向更通用智能发展的重要力量。未来,我们或许能够看到一个更加智能、更加灵活的人工智能系统,它能够像人类一样处理来自不同感官的信息,并做出更加精准的决策。
多模态统一Transformer的出现,标志着AI正在向更通用的智能迈进。它不仅解决了传统多模态学习中存在的诸多问题,还为人工智能的未来发展开辟了新的道路。在这个充满挑战与机遇的时代,让我们共同期待多模态统一Transformer在更多领域的应用和拓展,为人类的进步和发展贡献更多的智慧和力量。