Spark 在反作弊聚类场景的实践
发布时间:2024-09-18
在互联网时代,垃圾信息和作弊行为已成为各大平台面临的严峻挑战。以知乎为例,每天产生近千万的写行为,如何快速有效地识别和处理这些垃圾内容成为了一个棘手的问题。Spark作为一种高性能的分布式计算框架,在反作弊聚类场景中展现出了巨大的潜力。
Spark的核心优势在于其基于内存的计算模式和高效的DAG执行引擎。与传统的MapReduce相比,Spark能够将中间结果和数据集存储在内存中,大大减少了磁盘I/O和网络通信的时间。同时,Spark提供了丰富的算子(如filter、flatMap等),支持更灵活的数据处理方式。这些特性使得Spark在处理大规模数据时能够实现比MapReduce快100倍以上的性能提升。
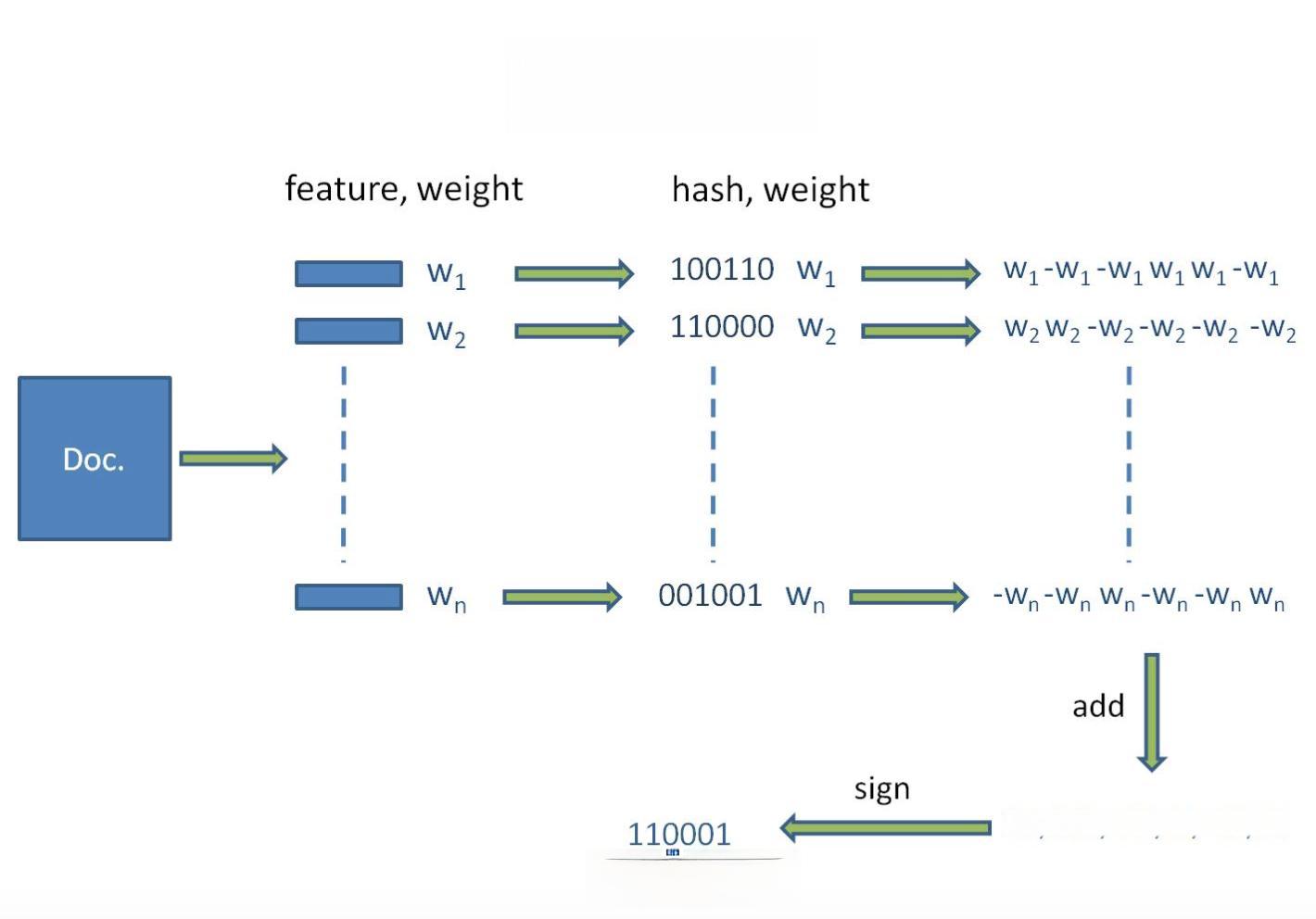
在反作弊聚类场景中,Spark的应用主要体现在内容聚类和行为聚类两个方面。内容聚类旨在将相似的内容聚集在一起,以识别批量生产的垃圾信息。知乎采用了一种基于图分割的方法,将每个文档视为图中的一个顶点,文档之间的相似度作为相连边的权重。通过设置合适的阈值,可以将相似的内容划分到同一个cluster中。在实际应用中,知乎使用了sim-hash算法来提高相似度计算的效率。sim-hash为输入的文本生成一个n位的指纹,对于近似的文本,其指纹也近似。通过比较指纹的汉明距离,可以快速判断两个文本的相似度。
行为聚类则是将用户的行为路径以文本的方式表达出来,通过文本相似度聚类将相似的行为聚集在一起。知乎的做法是,以用户的一个post行为为单位,取前后至少两个请求,并计算每个行为之间的时间间隔,将用户的行为序列表达成由“请求路径|请求方法|与上一次请求的时间间隔”构成的文本组合。这种方法可以有效识别出异常的行为模式。
Spark的应用极大地提升了反作弊聚类的效率。以知乎的私信场景为例,如果用单进程去比较每天10万条私信的相似度,需要进行近似笛卡尔积的计算,耗时接近27小时。而使用Spark后,聚类可以在1-3分钟之内完成。这种效率的提升不仅节省了大量计算资源,更重要的是能够及时发现和处理垃圾信息,提升用户体验。
Spark在反作弊聚类中的应用展示了其在大数据处理领域的强大能力。通过将复杂的聚类问题转化为分布式计算任务,Spark能够快速处理海量数据,识别出潜在的作弊行为。未来,随着Spark Streaming等实时处理能力的加入,反作弊系统有望实现更快速、更精准的响应,为互联网平台提供更强大的安全保障。