第三章 语法分析
发布时间:2024-09-18
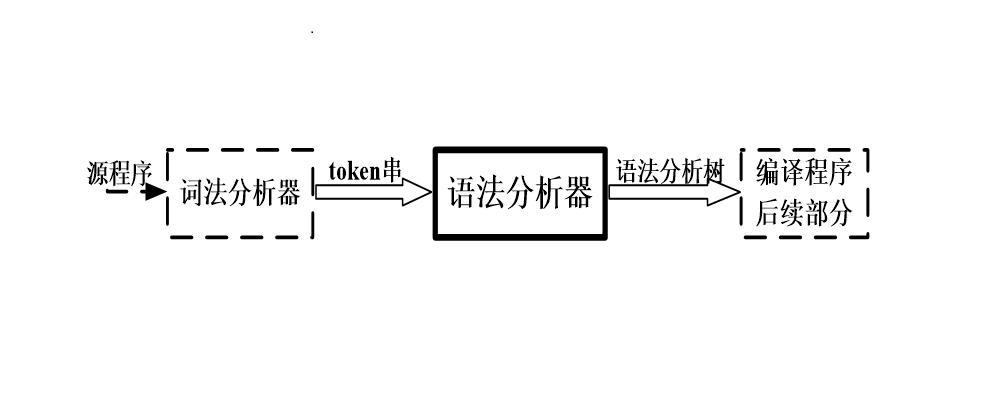
自然语言处理(NLP)是人工智能领域的一个重要分支,旨在使计算机能够理解、解释和处理人类语言。在这个复杂的任务中,语法分析扮演着至关重要的角色。它通过对句子结构进行解析和建模,帮助计算机理解人类语言的语法规则,进而提取出文本中的重要信息。
语法分析的核心目标是识别句子中的语法结构,包括词性标注、短语结构分析和依存关系分析等。词性标注是指识别句子中每个词语的语法功能,如名词、动词、形容词等。短语结构分析则关注句子中的短语结构和句法关系,如主谓关系、动宾关系等。依存关系分析则侧重于识别句子中词语之间的依赖关系,如主语依赖于谓词、宾语依赖于动词等。
在方法论上,语法分析可以分为基于规则的方法和基于统计的方法两大类。 基于规则的方法依赖于人工制定的语法规则和语义规则 ,而 基于统计的方法则通过训练模型来学习语法规则和语义规则 。随着深度学习技术的发展,基于深度学习的句法分析方法,如循环神经网络(RNN)、长短期记忆网络(LSTM)和Transformer等,正在成为主流。
语法分析在NLP中有着广泛的应用。在信息抽取领域,它可以帮助识别句子中的主谓宾结构、定语从句等语法结构,从而提取出句子中的关键信息和实体关系。在机器翻译领域,语法分析可以帮助计算机理解源语言句子的结构和语法关系,从而更准确地翻译成目标语言。在问答系统中,语法分析可以帮助理解用户提出的问题,并从文本中找到相关的答案。在情感分析领域,语法分析可以帮助分析句子中的情感词、修饰词等语法结构,从而更准确地理解句子的情感倾向和情感强度。
然而, 语法分析也面临着诸多挑战 。首先,语言的复杂性使得构建完整的语法规则或模型变得非常困难。其次,不同语言的语法规则和表达方式存在很大的差异,这要求我们针对不同的语言进行定制化开发。此外,由于语言本身的动态性和演化性,语法规则和语义规则可能会随着时间和社会环境的变化而变化。因此,我们需要不断地更新和调整我们的模型和算法以适应这些变化。
尽管面临诸多挑战,但随着深度学习技术的不断发展和数据集的不断扩大,基于深度学习的句法分析方法正在取得显著进展。结合语义理解和知识图谱等技术,我们有望更好地理解句子的含义和上下文信息,进一步提高句法分析的准确率和鲁棒性。
总的来说,语法分析是自然语言处理中的一项关键技术,它有助于我们更好地理解语言的结构和意义。随着技术的不断进步和应用场景的不断扩展,我们期待着在句法分析领域涌现更多的创新和突破,推动自然语言处理技术的发展和应用。