车载语音研究:大模型上车,语音交互是智能座舱场景第一站
发布时间:2024-09-18
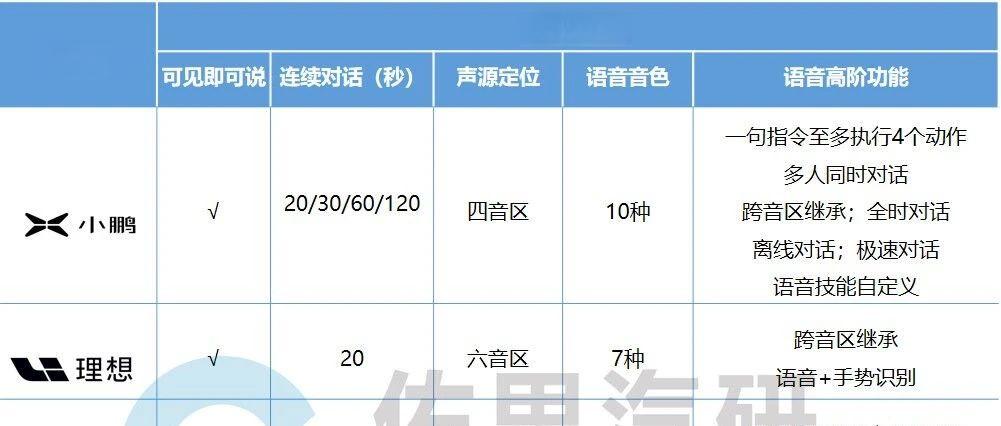
车载语音交互技术正在经历一场革命性的变革。随着人工智能大模型的兴起,智能座舱正在成为人车交互的新战场。合众新能源汽车股份有限公司软件开发总工程师蔡勇在2023第五届智能座舱与用户体验大会上指出,语音作为座舱的第一交互方式,正在迎来新的发展机遇。
车载语音交互技术的核心包括唤醒、聆听、理解和播报四个环节。在唤醒方面,声源定位技术已经从双音区发展到四音区,能够更准确地识别说话者的位置。同时,One-Shot技术的支持使得用户可以在唤醒词后直接说出指令,无需停顿。在聆听环节,全双工语音交互技术已经成为主流,能够实现真正的“边听边说”。在理解方面,支持一句话包含多个任务的理解能力大大提高了交互效率。而在播报环节,音色自定义和TTS个性化播报技术的应用,使得语音助手更加拟人化。
大模型的引入为车载语音交互带来了新的可能性。蔡勇表示,大模型具有通才、专业和自然三大特点。它不仅知识面广,还能在各个领域表现出深刻理解,同时交流方式非常自然,就像人与人之间的对话。在车载场景中,大模型可以作为内部工具提高工作效率,如进行数据和评价上的应用。更重要的是,大模型能够与车场景紧密结合,实现语音功能与智能驾驶的深度融合。
然而,大模型上车仍处于萌芽期,存在一些问题。目前主要以功能移植为主,与车辆功能的结合较少。蔡勇认为,未来应该重点关注语音功能与车场景和智能驾驶的深度融合,借助大模型使语音助手真正进入成长期。在成长期,大模型将发挥“车大脑”的功能,进行座舱功能的主动执行,并且是“最适合你”的。
尽管前景光明,车载语音交互技术仍面临诸多挑战。首先是技术层面的挑战,如声源定位的准确性、全双工语音交互的抗噪能力等。其次是用户体验的挑战,如何在保证安全的前提下,提供更加自然、高效的交互体验。此外,数据隐私和安全也是不容忽视的问题。
展望未来,车载语音交互技术将朝着更加智能、个性化和安全的方向发展。随着5G、边缘计算等技术的成熟,车载语音交互将能够更好地利用云端资源,实现更强大的功能。同时,多模态交互技术的应用,将使得人车交互更加自然和高效。最终,车载语音交互有望成为连接人、车、路的重要纽带,为智能交通系统的建设提供有力支撑。
在这个过程中,汽车制造商、技术供应商和监管部门需要密切合作,共同推动车载语音交互技术的健康发展。只有这样,我们才能真正实现“让汽车更懂你”的愿景,开启智能出行的新时代。