从零开始了解推荐系统全貌
发布时间:2024-09-19
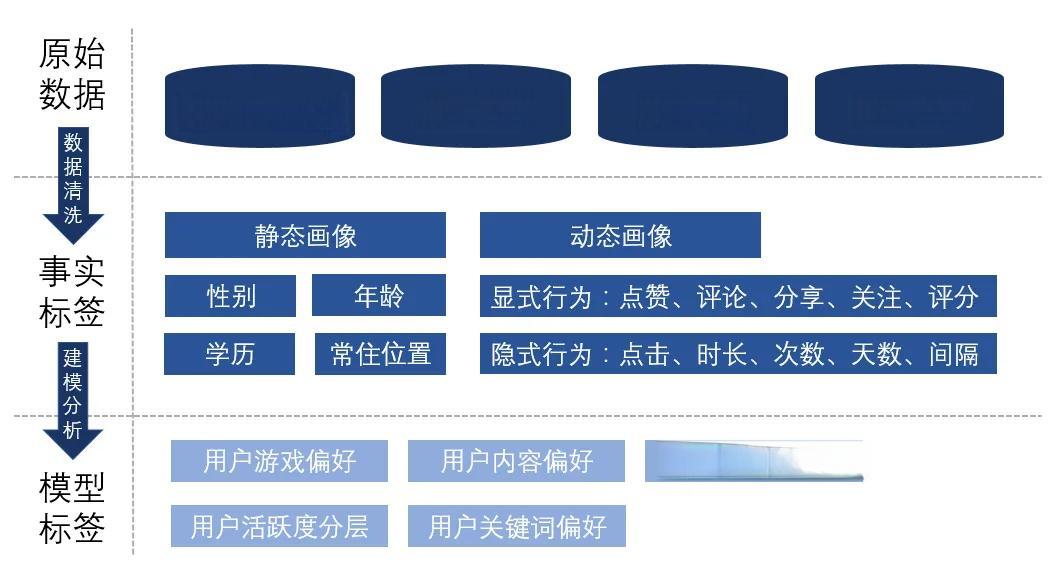
在互联网时代,我们每天都会接触到各种推荐系统,从电商网站的商品推荐到社交媒体的信息流,再到视频平台的影片推荐。这些系统背后的核心技术就是推荐算法。让我们以电影推荐系统为例,来一窥推荐系统的全貌。
电影推荐系统的核心原理
电影推荐系统的目标是根据用户的历史行为和偏好,预测用户可能感兴趣的电影,并进行推荐。这个过程涉及几个关键步骤:
-
数据收集:收集用户行为数据,如观看历史、评分、搜索记录等,以及电影的元数据,如类型、导演、演员等。
-
特征提取:从收集到的数据中提取有用的特征。例如,可以使用自然语言处理技术从电影简介中提取关键词,或者计算用户之间的相似度。
-
模型训练:利用提取的特征训练推荐模型。常见的模型包括基于内容的推荐和协同过滤。
-
推荐生成:根据训练好的模型,为用户生成个性化的推荐列表。
基于内容的推荐方法
基于内容的推荐方法主要依赖于电影本身的特征。以电影《盗梦空间》为例,系统可能会提取出“科幻”、“悬疑”、“克里斯托弗·诺兰”等关键词。当用户观看过这部电影后,系统会推荐具有相似特征的其他电影,如《星际穿越》或《记忆碎片》。
这种方法的优点是推荐结果具有较强的可解释性,用户可以清楚地理解为什么被推荐这些电影。然而,它也存在局限性,比如难以发现跨类型的潜在兴趣。
协同过滤推荐技术解析
协同过滤是一种基于用户行为的推荐方法。它主要有两种实现方式:
-
基于用户的协同过滤:找到与目标用户兴趣相似的其他用户,然后推荐这些用户喜欢的电影。例如,如果用户A喜欢《盗梦空间》和《星际穿越》,用户B喜欢《盗梦空间》和《记忆碎片》,那么系统可能会向用户A推荐《记忆碎片》。
-
基于物品的协同过滤:计算电影之间的相似度,然后推荐与用户已喜欢电影相似的其他电影。这种方法在Netflix等大型视频平台中广泛应用。
协同过滤的优势在于能够发现用户潜在的兴趣,但同时也面临数据稀疏性和冷启动等问题。
Netflix推荐系统的创新实践
Netflix的推荐系统是一个典型的协同过滤应用。它会考虑用户的观看历史、评分、搜索行为等多方面因素,同时也会利用电影的元数据。Netflix还会根据用户的观看时间和设备偏好等因素进行个性化推荐。
Netflix的推荐系统并非一成不变,而是不断学习和优化。每次用户观看或评分一部电影,系统都会更新模型,以更准确地预测用户的兴趣。
推荐系统面临的挑战与未来发展方向
尽管推荐系统已经取得了巨大进步,但它仍然面临许多挑战。数据稀疏性、冷启动问题、推荐多样性与新颖性等都是需要解决的问题。未来,推荐系统可能会更多地结合深度学习等先进技术,以更好地理解和预测用户行为。
推荐系统不仅改变了我们获取信息和娱乐的方式,也在重塑整个互联网生态。了解推荐系统的工作原理,不仅能帮助我们更好地利用这些服务,也能让我们更深入地思考技术对社会的影响。