模型评估与选择
发布时间:2024-09-18
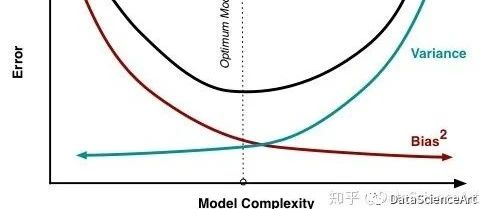
在机器学习项目中,选择合适的模型是至关重要的一步。然而,面对众多的模型选项和评估指标,许多初学者常常感到困惑。本文将为您揭示模型评估与选择的奥秘,帮助您在实际应用中做出明智的决策。
模型评估为何如此关键
模型评估是机器学习流程中不可或缺的一环。 它不仅帮助我们了解模型在未知数据上的表现,还能指导我们进行模型选择和优化。正如科学家门捷列夫所说:“没有测量,就没有科学。”在AI领域,我们同样需要定量的数值化指标来指导模型选择和训练。
常用模型评估指标及其应用场景
在模型评估中,我们通常会遇到以下几种常见的指标:
-
准确率(Accuracy):最直观的评估指标,适用于类别均衡的数据集。然而,在类别严重不均衡的情况下,准确率可能会产生误导。
-
精确率(Precision)和召回率(Recall):在二分类问题中,精确率关注预测为正类的样本中真正为正类的比例,而召回率则关注所有正类样本中被正确预测的比例。在垃圾邮件识别等场景中,我们可能更关注精确率,以避免将正常邮件误判为垃圾邮件。
-
F1分数(F1 Score):综合考虑精确率和召回率的指标,适用于需要平衡两者的情况。F1分数越高,说明模型的性能越好。
-
ROC曲线和AUC值:ROC曲线反映了模型在不同阈值下的性能,AUC值则量化了模型的排序能力。在医疗诊断等场景中,我们可能更关注AUC值,以确保模型能够准确识别小众样本。
-
均方误差(MSE)和均方根误差(RMSE):适用于回归问题,衡量预测值与实际值之间的偏差。在房价预测等场景中,这些指标可以帮助我们评估模型的预测精度。
如何选择合适的模型
在选择模型时,我们应该遵循以下原则:
-
简单性原则:在满足需求的前提下,应选择更简单的模型。简单的模型通常更容易理解和实现,并且泛化能力更强。
-
可解释性原则:对于某些应用场景,模型的解释性很重要。可解释性强的模型有助于我们更好地理解模型的决策过程和结果的可靠性。
-
性能优先原则:在某些情况下,我们可能需要牺牲模型的简单性和可解释性,以换取更高的预测性能。
在实际应用中,我们可以通过交叉验证等技术来评估模型的泛化能力,避免过拟合和欠拟合问题。同时,我们还需要考虑数据的平衡性、特征的重要性等因素,综合判断模型的适用性。
模型评估与选择的注意事项
在进行模型评估与选择时,我们还需要注意以下几点:
-
评估指标的选择应该基于具体的应用场景和业务需求。例如,在金融风控领域,我们可能更关注召回率,以确保不会漏掉任何有风险的行为。
-
单一的评估指标可能无法全面反映模型的性能。我们应该结合多个指标进行综合评估。
-
模型的性能可能会受到数据集划分、特征选择等因素的影响。因此,在评估模型时,我们应该尽可能使用交叉验证等方法来减少偏差。
-
在实际应用中,我们还需要考虑模型的训练时间、部署成本等因素。有时候,一个性能略低但易于部署的模型可能比一个高性能但复杂的模型更合适。
模型评估与选择是一个需要经验和技巧的过程。通过不断实践和学习,我们才能在众多模型中找到最适合我们需求的那个。记住,没有完美的模型,只有最适合当前任务的模型。在机器学习的道路上,保持开放和探索的心态,你将能够做出更明智的选择。