深度学习:tf.keras实现模型搭建、模型训练和预测
发布时间:2024-09-18
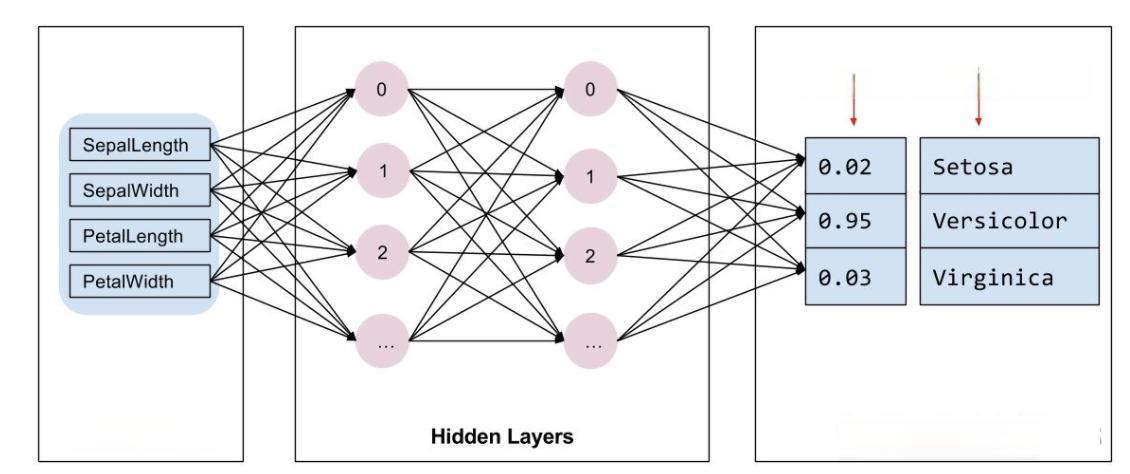
在深度学习领域,手写数字识别是一个经典且有趣的任务。通过这个任务,我们可以深入了解如何使用TensorFlow和Keras构建、训练和评估一个深度学习模型。在这个案例中,我们将使用著名的MNIST数据集,它包含了60000个训练样本和10000个测试样本,每个样本都是28x28像素的灰度图像,代表0到9的数字。
准备MNIST数据集
首先,我们需要加载和预处理数据。Keras提供了一个方便的API来加载MNIST数据集:
from tensorflow.keras.datasets import mnist
import numpy as np
# 加载数据
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 归一化
X_train = X_train / 255.0
X_test = X_test / 255.0
# 将图像数据从(28, 28)转换为(28, 28, 1)
X_train = np.expand_dims(X_train, -1)
X_test = np.expand_dims(X_test, -1)
构建卷积神经网络模型
接下来,我们将使用Keras的Sequential API来构建一个简单的卷积神经网络(CNN)模型。CNN特别适合处理图像数据,因为它可以捕捉局部特征。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
model = Sequential([
Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1)),
MaxPooling2D(pool_size=(2, 2)),
Conv2D(64, kernel_size=(3, 3), activation='relu'),
MaxPooling2D(pool_size=(2, 2)),
Flatten(),
Dense(128, activation='relu'),
Dense(10, activation='softmax')
])
在这个模型中,我们使用了两个卷积层(Conv2D)来提取特征,两个最大池化层(MaxPooling2D)来降低维度,一个全连接层(Dense)来进一步处理特征,最后是一个输出层,使用softmax激活函数来产生概率分布。
编译和训练模型
在训练模型之前,我们需要编译它,指定损失函数、优化器和评估指标:
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
然后,我们可以使用
fit
方法来训练模型:
model.fit(X_train, y_train, epochs=10, batch_size=128)
在训练过程中,模型会自动调整权重以最小化损失函数。我们可以通过观察训练过程中的损失值和准确率来评估模型的性能。
评估模型性能
训练完成后,我们可以使用测试数据集来评估模型的性能:
test_loss, test_acc = model.evaluate(X_test, y_test)
print(f'Test accuracy: {test_acc}')
使用模型进行预测
最后,我们可以使用训练好的模型来预测新的图像:
import matplotlib.pyplot as plt
# 选择一个测试样本
img = X_test[0]
# 显示图像
plt.imshow(img.squeeze(), cmap='gray')
plt.show()
# 预测
prediction = model.predict(np.expand_dims(img, axis=0))
predicted_digit = np.argmax(prediction)
print(f'Predicted digit: {predicted_digit}')
通过这个简单的案例,我们展示了如何使用tf.keras构建、训练和评估一个深度学习模型。Keras的Sequential API使得模型构建变得非常直观和简单,而TensorFlow则提供了强大的后端支持。这种方法可以很容易地扩展到更复杂的模型和更大的数据集,为深度学习的应用提供了无限可能。