全面了解R语言中的k-means如何聚类?
发布时间:2024-09-02
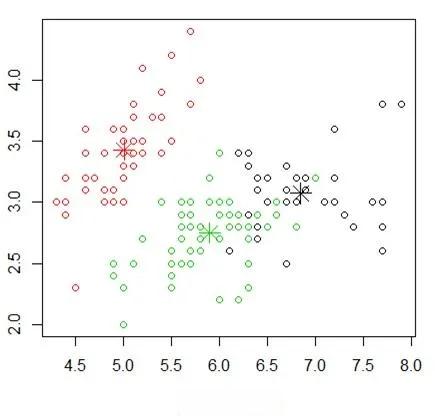
k-means聚类算法是无监督学习中的一种经典方法,广泛应用于数据挖掘和机器学习领域。在R语言中,k-means算法的实现非常简便,为数据分析师提供了强大的工具。
k-means算法的核心思想是将数据集划分为k个簇,使得簇内的数据点尽可能相似,而簇间的数据点尽可能不同。算法的具体步骤如下:
- 初始化:随机选择k个数据点作为初始聚类中心。
- 分配:将每个数据点分配给最近的聚类中心,形成k个簇。
- 更新:重新计算每个簇的中心点。
- 重复步骤2和3,直到聚类中心不再发生变化或达到最大迭代次数。
在R语言中,我们可以使用内置的kmeans()函数来实现k-means聚类。以USArrests数据集为例,我们可以这样进行聚类分析:
# 加载数据
df <- USArrests
# 数据标准化
df <- scale(df)
# 执行k-means聚类
km <- kmeans(df, centers = 4, nstart = 25)
# 查看聚类结果
km$cluster
这段代码将数据集分为4个簇,并返回每个州所属的簇编号。我们还可以使用fviz_cluster()函数可视化聚类结果,或者使用aggregate()函数计算每个簇的统计特征。
k-means算法具有计算速度快、适用于大数据集的优点。然而,它也存在一些局限性。首先,我们需要事先确定聚类的数量k,这在实际应用中往往难以确定。其次,k-means对初始聚类中心的选择比较敏感,不同的初始值可能导致不同的聚类结果。此外,k-means对异常值和非凸形簇的处理效果不佳。
为了克服这些局限性,研究者们提出了多种改进方法。其中,k-means++算法通过优化初始聚类中心的选择,显著提高了聚类的稳定性和质量。具体步骤如下:
- 随机选择一个数据点作为第一个聚类中心。
- 对于每个数据点,计算其到最近聚类中心的距离。
- 选择一个新的数据点作为聚类中心,选择的概率与距离的平方成正比。
- 重复步骤2和3,直到选择出k个聚类中心。
此外,还有Mini Batch K-means算法,它通过每次只处理数据集的一小部分来加速聚类过程,特别适合处理大规模数据集。
总的来说,k-means聚类算法在R语言中的应用非常广泛,为数据分析师提供了强大的工具。通过理解算法原理、合理选择参数,并结合改进方法,我们可以充分发挥k-means算法的优势,解决各种实际问题。