图解自注意力机制(Self-Attention)
发布时间:2024-09-19
当你走进一间陌生的房间,你的目光会自然而然地被某些物体吸引。这并不是随机的,而是你的大脑在瞬间对周围环境进行了评估,并将注意力集中在最重要的信息上。这种能力被称为注意力机制,而它在人工智能领域也有着重要的应用。
在深度学习中,自注意力机制(Self-Attention)就是一种模仿人类注意力机制的方法。它允许模型在处理序列数据时,能够关注到序列中最重要的部分,而不仅仅是按照固定的顺序逐个处理元素。这种机制在自然语言处理、计算机视觉等多个领域都展现出了强大的能力。
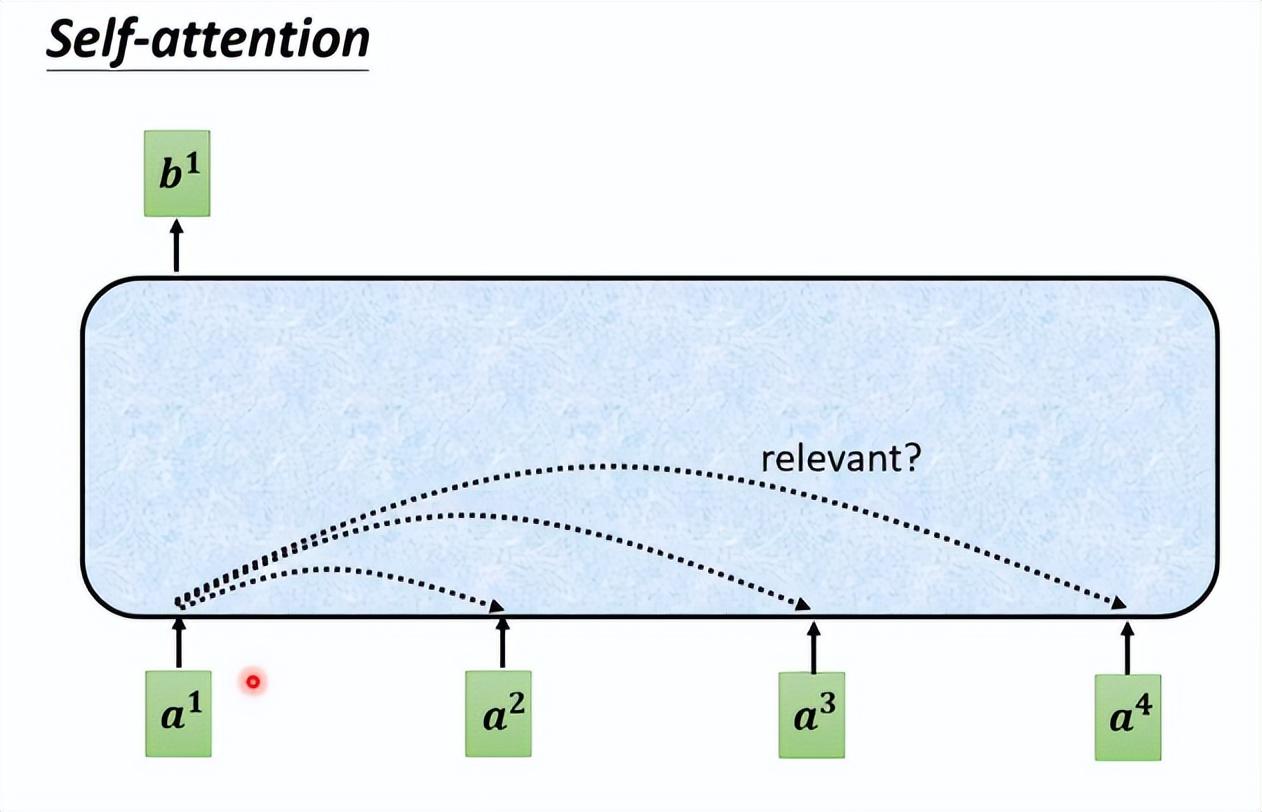
自注意力机制的核心在于三个关键概念:查询(Query)、键(Key)和值(Value)。我们可以将它们类比为人类视觉系统中的“关注点”、“参照物”和“信息”。当我们观察一个场景时,我们的大脑会快速扫描整个场景,找到最值得关注的物体(查询),然后根据周围的参照物(键)来确定这个物体的重要性,并提取相关信息(值)。
在自注意力机制中,这个过程是通过数学运算来实现的。首先,每个输入元素都会被转换成查询、键和值三个向量。然后,每个查询向量会与所有键向量进行比较,计算它们之间的相似度。这个相似度就像是一个权重,决定了每个值向量对最终输出的贡献程度。
具体来说,计算过程可以分为几个步骤:
-
初始化查询、键和值向量。这通常是通过将输入向量与一组权重矩阵相乘来实现的。
-
计算注意力得分。这一步是通过将查询向量与每个键向量进行点积来完成的。点积的结果反映了查询与键之间的相似度。
-
对得分进行缩放和归一化。通常会将得分除以一个常数(通常是键向量维度的平方根),然后通过softmax函数将所有得分转换为概率分布。
-
计算加权和。将每个值向量乘以其对应的权重,然后将所有结果相加,得到最终的输出向量。
这个过程看似复杂,但实际上可以非常高效地并行计算。这也是自注意力机制相比传统循环神经网络(RNN)的一大优势。RNN需要按顺序处理序列中的每个元素,而自注意力机制可以同时考虑序列中的所有元素。
自注意力机制与传统的注意力机制(Attention)有所不同。传统注意力机制通常用于两个不同的序列之间,比如在机器翻译中,将源语言序列映射到目标语言序列。而自注意力机制则是用于序列内部,关注序列中元素之间的关系。这种机制更擅长捕捉长距离依赖关系,这也是它在处理自然语言等序列数据时表现出色的原因。
自注意力机制的优势主要体现在以下几个方面:
-
并行计算能力。自注意力机制可以同时处理序列中的所有元素,大大提高了计算效率。
-
捕捉长距离依赖。相比RNN,自注意力机制能够更好地处理序列中的长距离依赖关系。
-
灵活性。自注意力机制可以应用于不同类型的序列数据,并且可以容易地扩展到更长的序列。
-
参数少。相比复杂的神经网络结构,自注意力机制的参数量相对较少,降低了模型的复杂度。
自注意力机制在多个领域都有广泛应用。在自然语言处理中,它被用于机器翻译、文本摘要、情感分析等任务。在计算机视觉中,自注意力机制可以帮助模型捕捉图像中远距离的依赖关系。在时间序列分析和音频处理中,它也能有效地捕捉长期依赖关系。
总的来说,自注意力机制通过模仿人类的注意力机制,为深度学习模型提供了一种强大的工具,使它们能够更智能、更高效地处理复杂的数据。随着研究的深入,我们有理由相信,自注意力机制将在更多领域展现出其独特的优势,推动人工智能技术的进一步发展。