如何降低Transformer模型的计算复杂度?
发布时间:2024-09-01
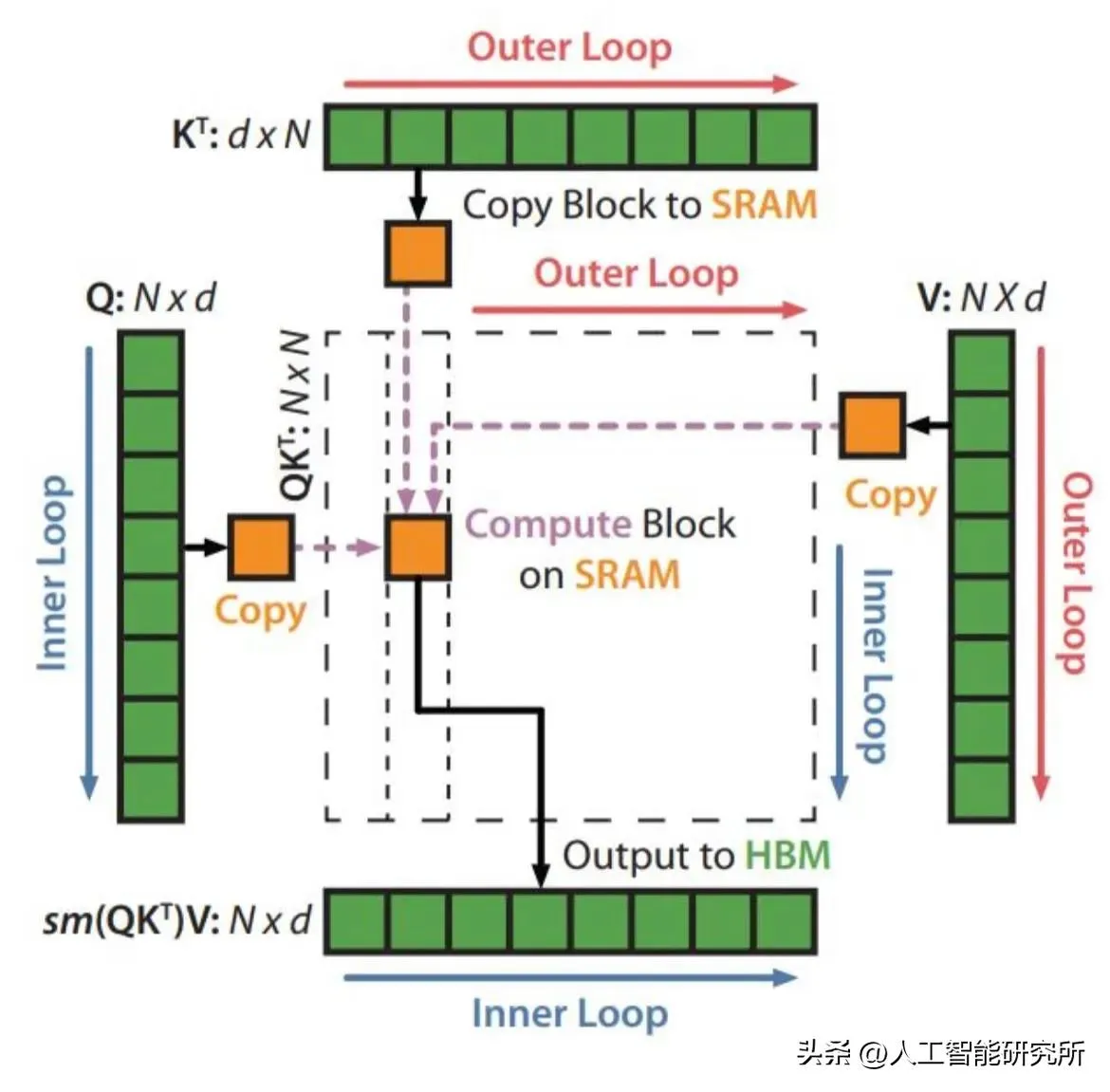
Transformer模型因其强大的序列建模能力在自然语言处理领域取得了巨大成功。然而,随着序列长度的增加,其计算复杂度呈平方增长,严重限制了模型在长序列任务上的应用。如何降低Transformer的计算复杂度,成为当前研究的热点问题。
Transformer的计算复杂度主要源于其自注意力机制。在标准的Softmax Attention中,每个token需要与序列中的所有其他token进行交互,导致计算复杂度为O(N^2),其中N为序列长度。这种高复杂度使得Transformer难以处理数万个token的长文本任务,如论文阅读、书籍阅读等。
为了解决这一问题,研究者们提出了多种优化方法。其中,稀疏注意力(Sparse Attention)是一种有效降低计算复杂度的策略。稀疏注意力通过限制每个token只与部分token进行交互,将复杂度降低至O(N)。例如,Strided Attention允许每个token只关注其左侧相邻的L个token,而Fixed Attention则允许每个token关注固定间隔的token。这些方法通过减少参与计算的token数量,显著降低了计算量。
另一种流行的优化方法是分块注意力(Blockwise Attention)。这种方法将长序列分割成多个短序列块,每个块只与相邻的块进行交互。例如,当序列长度为1024,分块数为8时,每个块的长度为128。这种方法将全局注意力转换为局部注意力,大大减少了计算量。然而,分块注意力可能会损失一些全局信息,需要在局部信息和全局信息之间权衡。
除了上述方法,还有一些其他优化策略,如层次注意力(Hierarchical Attention)和稀疏因子化自注意力(Factorized Self-Attention)。层次注意力通过在不同层级上对输入序列进行建模,既保留了全局信息,又降低了计算复杂度。稀疏因子化自注意力则通过将注意力机制分解为多个低复杂度的子机制,实现了计算效率和模型表达能力的平衡。
这些优化方法各有优缺点。稀疏注意力和分块注意力能够显著降低计算复杂度,但可能会损失一些全局信息。层次注意力和稀疏因子化自注意力则在保持模型表达能力的同时降低了计算复杂度,但实现起来相对复杂。研究者们正在探索如何在效率和性能之间找到最佳平衡点。
当前,降低Transformer计算复杂度的研究仍在快速发展。除了优化注意力机制,研究者们还在探索其他方向,如模型量化、知识蒸馏等。随着硬件技术的进步,如GPU和TPU的快速发展,也为处理大规模序列提供了新的可能性。
总的来说,降低Transformer计算复杂度是一个多方面的问题,需要从算法、硬件等多个角度综合考虑。未来,我们有望看到更加高效、灵活的Transformer变体,为处理大规模序列任务提供更强大的工具。