爱奇艺 CTR 场景下的 GPU 推理性能优化
发布时间:2024-09-18
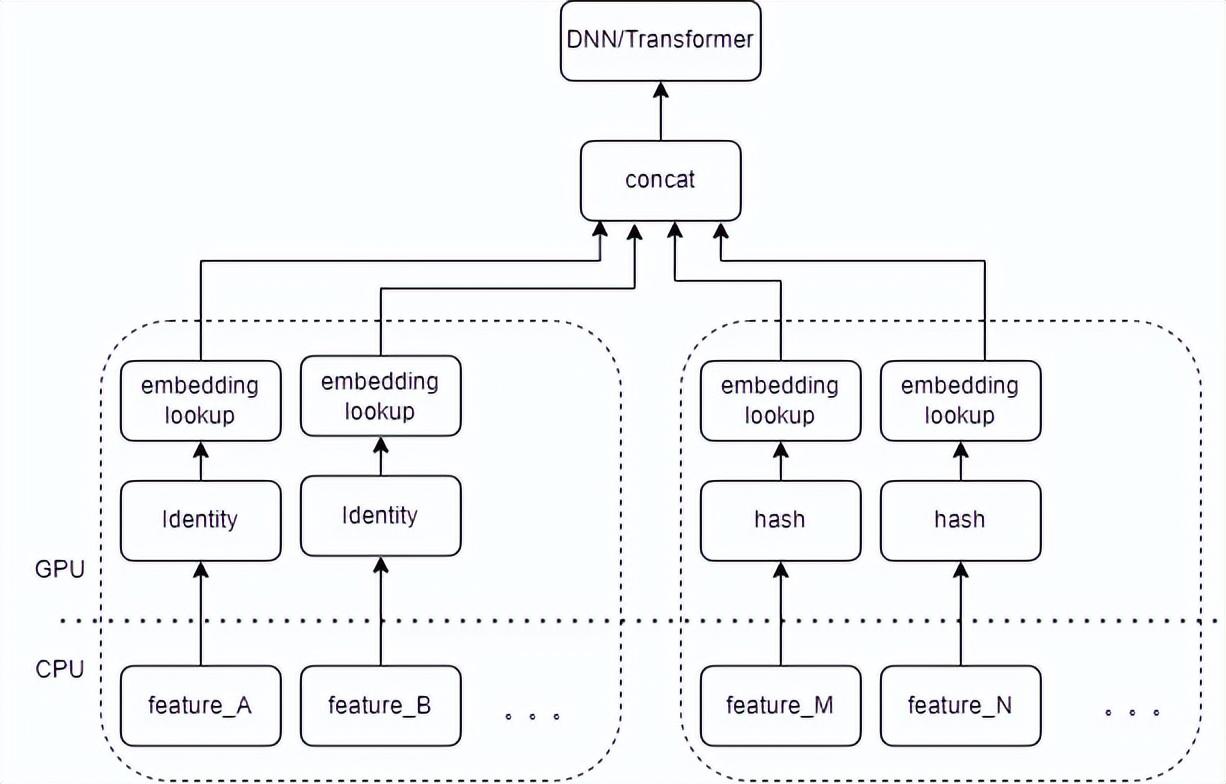
GPU正在成为推荐系统性能优化的关键利器。随着深度学习技术的蓬勃发展,以GPU为代表的专用芯片凭借其强大的高性能计算能力和日益降低的成本,在机器学习领域得到广泛应用,推动了推荐系统向更精准、更高效的演进。
GPU在推荐系统中的应用主要源于其独特的架构优势。相比传统的CPU,GPU拥有更多的计算单元和更宽的数据通路,特别适合处理大规模并行计算任务。在推荐系统中,GPU可以显著加速模型训练和推理过程,特别是在处理大规模稀疏特征时表现出色。然而,将GPU应用于推荐系统也面临着诸多挑战。首先是模型规模问题,推荐系统中的Embedding表往往非常庞大,可能超出单个GPU的显存容量。其次是数据传输瓶颈,GPU与CPU之间的数据交换可能会成为性能瓶颈。此外,如何在保证模型效果的同时充分利用GPU的并行计算能力,也是需要解决的关键问题。
以爱奇艺的CTR(Click-Through Rate,点击率)场景为例,GPU推理性能优化主要围绕以下几个方面展开:
-
模型结构优化:通过减少交叉特征、精简特征等方式压缩模型规模,使其更适合在GPU上运行。例如,采用Compositional Embedding等技术可以实现数个量级的模型参数压缩。
-
分布式Embedding:针对大规模Embedding表,采用分布式存储和计算策略。如NVIDIA的Merlin Distributed Embeddings(TFDE)插件,可以实现跨GPU的Embedding查找和更新,显著提升处理大规模数据的能力。
-
算子优化:针对推荐系统中常见的算子进行优化,如稀疏矩阵乘法等,以充分利用GPU的并行计算能力。例如,OneFlow的OneEmbedding组件在DCN、DeepFM等模型上的性能大幅超过NVIDIA HugeCTR。
-
混合精度训练:利用GPU对半精度浮点数的高效处理能力,采用混合精度训练技术,可以在不牺牲模型精度的情况下大幅提升训练速度。
-
数据流优化:针对推荐系统中数据量大、读取频繁的特点,优化数据加载和预处理流程,减少GPU等待时间。如NVIDIA的Merlin Data Loader可以显著加速训练数据的读取过程。
-
系统架构优化:采用层次化参数服务器(HPS)等技术,优化模型的部署和推理过程。如Merlin Hierarchical Parameter Server可以实现高效的层次化参数更新和查找。
GPU在推荐系统中的应用正处于快速发展阶段。随着硬件技术的进步和软件优化的深入,GPU在推荐系统中的优势将得到进一步发挥。未来,我们可以期待看到更多针对推荐系统特点的GPU专用架构和优化技术,推动推荐系统的性能和效率达到新的高度。同时,如何在保证模型效果的同时充分利用GPU的并行计算能力,以及如何平衡GPU和CPU的计算负载,仍将是未来研究和实践的重点方向。