为什么尽量不要使用机器学习中的交叉验证
发布时间:2024-09-19
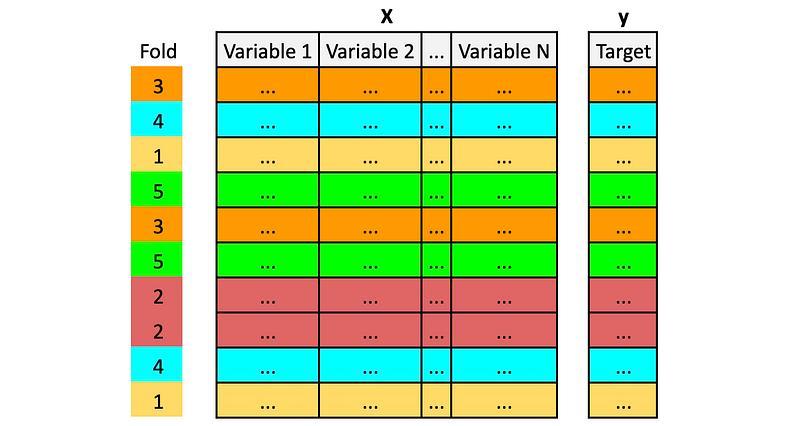
交叉验证是机器学习中常用的一种评估模型泛化能力的方法 ,但这种方法并非完美无缺。事实上,在某些情况下,我们可能需要谨慎使用交叉验证,甚至考虑其他替代方案。
首先, 交叉验证的计算成本是一个不容忽视的问题 。以K折交叉验证为例,我们需要将数据集分成K份,然后进行K次模型训练和验证。这意味着我们需要训练K个模型,这在数据量较大或模型复杂度较高时可能会导致巨大的计算负担。例如,在留一法(Leave One Out Cross Validation,LOOCV)中,如果数据集包含1000个样本,我们就需要训练1000个模型,这无疑会消耗大量的计算资源和时间。
其次, 交叉验证可能会导致模型过拟合 ,尤其是在数据集较小的情况下。虽然交叉验证的初衷是为了防止过拟合,但在某些情况下,它可能会适得其反。例如,在K折交叉验证中,如果K值选择不当,可能会导致训练集和验证集的分布不一致,从而影响模型的泛化能力。此外,如果在模型选择过程中过度依赖交叉验证的结果,可能会导致模型在训练数据上表现良好,但在新数据上表现不佳。
第三, 交叉验证的结果可能受到随机性的影响 ,导致结果不稳定。即使我们使用相同的K折交叉验证方法,不同的数据划分方式也可能导致不同的结果。这种不稳定性可能会给模型评估带来不确定性,特别是在数据集较小或模型对数据敏感的情况下。
最后, 交叉验证可能无法完全反映模型在实际应用中的表现 。交叉验证是在有限的数据集上进行的,而实际应用中可能会遇到更多样化和复杂的数据。此外,交叉验证通常是在静态数据集上进行的,而实际应用中的数据可能是动态变化的。因此,即使一个模型在交叉验证中表现良好,也不能保证它在实际应用中也能保持同样的性能。
那么,我们应该如何权衡交叉验证的利弊呢?在数据量较大且计算资源充足的情况下,交叉验证仍然是一个有效的模型评估方法。但在数据量较小或计算资源有限的情况下,我们可能需要考虑其他替代方案,如留出法(Holdout Validation)或自助法(Bootstrap Validation)。此外,我们还可以通过增加数据量、使用数据增强技术或简化模型来减少对交叉验证的依赖。
总的来说,交叉验证是一种有用的工具,但并非万能的。在实际应用中,我们需要根据具体情况权衡交叉验证的利弊,并结合其他方法来全面评估模型的性能。只有这样,我们才能构建出真正具有泛化能力的机器学习模型。