详解个性化推荐五大最常用算法
发布时间:2024-09-18
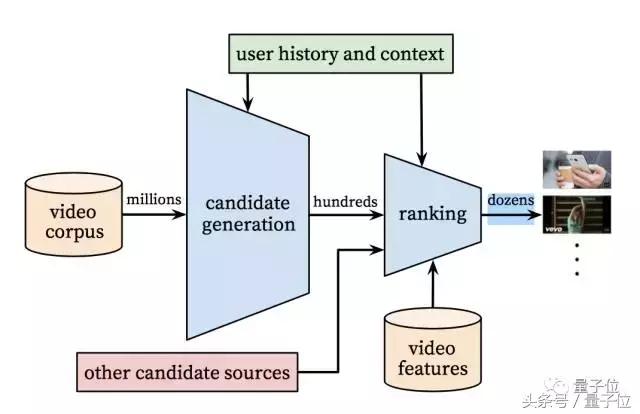
在当今信息爆炸的时代,个性化推荐系统已成为连接用户与海量信息的关键桥梁。从电商网站的商品推荐到社交媒体的信息流,再到视频平台的观看建议,个性化推荐算法无处不在,深刻影响着我们的日常生活。那么,这些神奇的算法究竟是如何工作的呢?让我们一起来揭开它们的神秘面纱。
协同过滤算法如何预测用户喜好
协同过滤是最早也是最流行的推荐算法之一。它通过分析用户之间的相似性或物品之间的相似性来实现个性化推荐。具体来说,协同过滤可以分为两种形式:用户基于协同过滤和物品基于协同过滤。
用户基于协同过滤侧重于寻找相似的用户,根据这些用户的喜好来预测目标用户可能感兴趣的物品。例如,如果用户A与用户B在多数物品上的评分高度一致,系统就会认为他们有类似的喜好。当用户A对某个尚未评分的物品表示出兴趣时,系统会参考用户B的评分给出推荐。
物品基于协同过滤则是通过项目之间的相似性来进行推荐。如果一个用户对某个物品评价很高,那么系统会寻找与这个物品相似的其他物品推荐给这个用户。这种算法相比用户基于协同过滤对新用户的适应性更好。
内容推荐算法如何挖掘用户兴趣
内容推荐算法是依据用户之前喜欢的物品的内容特征进行推荐。算法分析用户过去喜欢或选择的物品特征,从而预测出用户可能喜欢的其他物品。例如,在推荐图书时,可能会考虑图书的作者、类型、出版年份等要素。如果一个用户之前喜欢了很多科幻小说,那么系统将提高其他具有相似特征图书的推荐优先级。
混合推荐系统如何提升推荐质量
混合推荐系统结合了协同过滤和内容推荐算法,以解决单独使用这些方法时可能出现的问题。例如,它们可以减少冷启动问题的影响,并提供更多样化的推荐。混合推荐系统可以通过不同方式结合算法,如将不同推荐产生的评分加权平均、将一个推荐作为主要推荐并用其他方式填补缺项等。
矩阵分解技术如何优化用户体验
矩阵分解技术是现代推荐系统所常用的技术,包括广泛应用的奇异值分解(SVD)等方法。这种技术通过分解用户-物品评分矩阵,抽取出隐含的特征表示。SVD将原始评分矩阵分解为几个具有较低维度的矩阵的乘积,这些较低维度的矩阵表示了用户和物品在隐含特征空间中的位置。通过降低特征空间的维度,不仅可以减少数据的存储和计算量,也能发现用户和物品在较低维度隐藏的关联性,优化用户的推荐体验。
深度学习如何革新推荐系统
基于深度学习的推荐算法通过模仿人脑处理信息的方式,对复杂的用户行为和项目关系建模,提供更加准确和个性化的推荐。这些算法通常使用一种或多种形式的神经网络来识别用户与物品之间的复杂模式和关系,如卷积神经网络(CNNs)或循环神经网络(RNNs)。深度学习模型能够学习到丰富的特征表达,这对于处理非结构化的数据,如文本、图片、音频等特别有效,从而可以提供更加丰富和精确的推荐内容。
随着技术的不断进步,未来的推荐系统预计将更加智能化、上下文感知,并能够适应不断变化的用户需求。我们可以期待,未来的推荐系统将能够更好地理解用户的意图,提供更加精准和个性化的推荐,从而在信息海洋中为用户指引方向。