秒懂大模型:利用vLLM和Ray框架实现多机多卡分布式在线推理
发布时间:2024-09-18
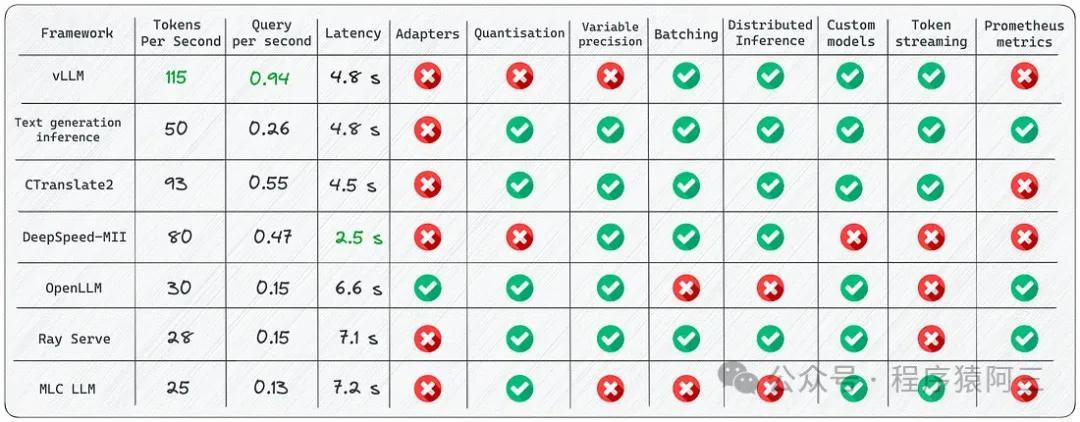
vLLM和Ray框架正在革新大语言模型的在线推理方式。vLLM是由伯克利大学LMSYS组织开源的高性能推理框架,而Ray则是分布式计算领域的明星框架。两者结合,为实现多机多卡的分布式在线推理提供了强大支持。
分布式在线推理的核心原理是将大型语言模型的计算任务分解到多个GPU上并行处理。这种方法能够显著提高推理速度和吞吐量,同时降低单个GPU的内存压力。以Qwen-14B-Chat模型为例,其模型权重大约28GB,而单个NVIDIA A10 GPU仅有24GB显存。通过分布式推理,我们可以将模型切分后部署到多个GPU上,每个GPU只加载模型的一部分,从而实现高效推理。
vLLM和Ray框架的协同工作是实现这一目标的关键。vLLM负责模型的推理核心,而Ray则负责分布式环境的协调和资源管理。具体来说,vLLM利用其独特的PagedAttention算法来优化注意力机制的计算过程,大幅提高推理效率。同时,vLLM还支持连续批处理(Continuous Batching)技术,能够在不牺牲延迟的情况下提高吞吐量。
Ray框架则负责构建和管理分布式集群。在部署vLLM分布式推理应用时,我们首先需要使用Ray启动一个分布式集群。Ray会自动处理节点间的通信、任务调度和资源分配。例如,在Kubernetes环境中,我们可以使用Ray来创建和管理多个Pod,每个Pod运行vLLM的一个实例。Ray的灵活调度能力确保了资源的高效利用和任务的快速执行。
这种分布式推理方法在实际应用中展现出显著优势。根据实验结果,vLLM相比Hugging Face Transformers的吞吐量提高了24倍,比TGI(Text Generation Inference)高出3.5倍。更重要的是,vLLM的内存管理效率极高,内存浪费比例低于4%,远低于传统方法60%-80%的浪费比例。
然而,实现高效的分布式在线推理也面临着挑战。首先是通信开销问题。在多机多卡环境下,节点间的通信可能会成为瓶颈。为了解决这个问题,vLLM采用了高效的通信策略,如NCCL(NVIDIA Collective Communications Library)和Gloo等,以减少通信延迟。
其次是模型并行策略的选择。vLLM支持张量并行和流水线并行两种方式。张量并行将模型权重切分到多个GPU上,而流水线并行则将模型的不同层分配到不同的GPU上。选择合适的并行策略对于平衡计算负载和通信开销至关重要。
最后是动态负载均衡问题。在实际应用场景中,请求的到达模式往往是不均匀的。vLLM通过其内置的调度器来动态调整任务分配,确保资源的高效利用。
展望未来,分布式在线推理技术将继续快速发展。随着大语言模型的规模不断扩大,对高效推理的需求将更加迫切。vLLM和Ray框架的结合为解决这一挑战提供了有力工具。我们有理由相信,在不久的将来,大规模语言模型的实时交互式应用将成为可能,为用户带来更加智能和便捷的体验。