突破AI性能瓶颈!揭秘LLaMA-MoE模型的高效神经元分配策略
发布时间:2024-09-01
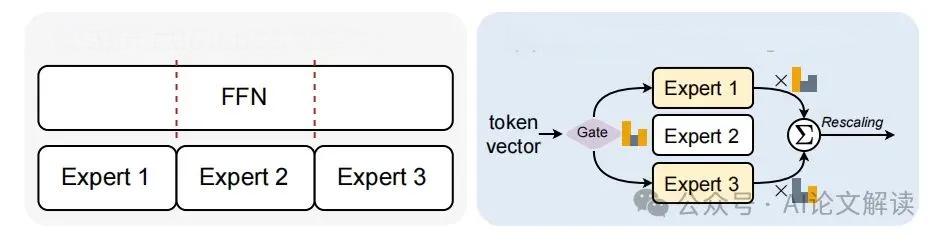
LLaMA-MoE模型通过将大型语言模型(LLM)转化为混合专家网络(MoE),成功突破了AI性能瓶颈。这一创新方法解决了训练MoE时常见的数据饥饿和不稳定性问题,为AI技术的发展开辟了新的道路。
LLaMA-MoE模型的核心在于其高效的神经元分配策略。首先,模型将原始的前馈网络(FFNs)参数划分为多个专家。这种划分可以是独立的,即每个专家拥有独立的参数集;也可以是共享的,允许多个专家共享部分参数。实验表明,随机划分方法在保持模型性能方面效果最佳,有助于平衡不同专家之间的负载。
其次,LLaMA-MoE模型采用了持续预训练策略。由于转换后的MoE模型结构与原始密集模型有所不同,直接使用可能会导致性能下降。因此,研究人员使用了200B个标记进行训练,以恢复和提升模型的语言建模能力。在预训练过程中,还采用了静态和动态两种数据采样策略,以优化模型性能。
此外,LLaMA-MoE模型通过激活部分模型参数来增强推理能力。每个输入token仅激活与其最相关的几个专家,减少了不必要的计算。这种稀疏激活方式不仅提高了计算效率,还能在保持高性能的同时降低推理成本。
LLaMA-MoE模型的性能优势主要体现在以下几个方面:
-
降低计算成本:相比传统的密集模型,MoE模型通过只激活部分参数来处理输入,显著降低了计算成本。例如,LLaMA-MoE-3.5B模型在激活参数量相当的情况下,显著优于类似的密集模型。
-
提高可解释性:由于每次仅有部分参数被激活,MoE模型的决策过程更加清晰,有助于研究人员追踪和解释模型的行为。
-
快速适应新任务:MoE模型可以根据输入动态选择合适的专家,实现快速而准确的推理。在实时翻译和智能助手等场景中,这一特性尤为重要。
-
良好的扩展性:随着数据量的增加,可以通过增加更多专家网络来提升模型性能,而无需对现有架构进行大规模修改。
LLaMA-MoE模型在实际应用中展现出巨大潜力。例如,在实时翻译场景中,传统模型可能需要大量计算资源来处理复杂的语言转换,而MoE模型则能够通过激活少量专家,快速处理翻译任务,降低延迟并提高响应速度。同样,在智能助手中,MoE模型可以根据用户的不同需求,动态分配计算资源,提供更加个性化和高效的服务。
然而,LLaMA-MoE模型的发展也面临着一些挑战。例如,模型的复杂性可能会增加调试和优化的难度。此外,如何在保持性能的同时进一步降低计算成本,也是未来研究的方向。
总的来说,LLaMA-MoE模型通过其创新的MoE架构,在保持高性能的同时有效降低了训练成本,提高了计算效率,并展示了出色的通用性和适用性。这一突破不仅为AI技术的发展提供了新的思路,也为更广泛的应用场景打开了大门。随着技术的不断进步,我们有理由相信,LLaMA-MoE模型将在自然语言处理领域发挥越来越重要的作用,推动人工智能技术的持续发展。