一文搞懂什么是Hadoop(转载)
发布时间:2024-08-29
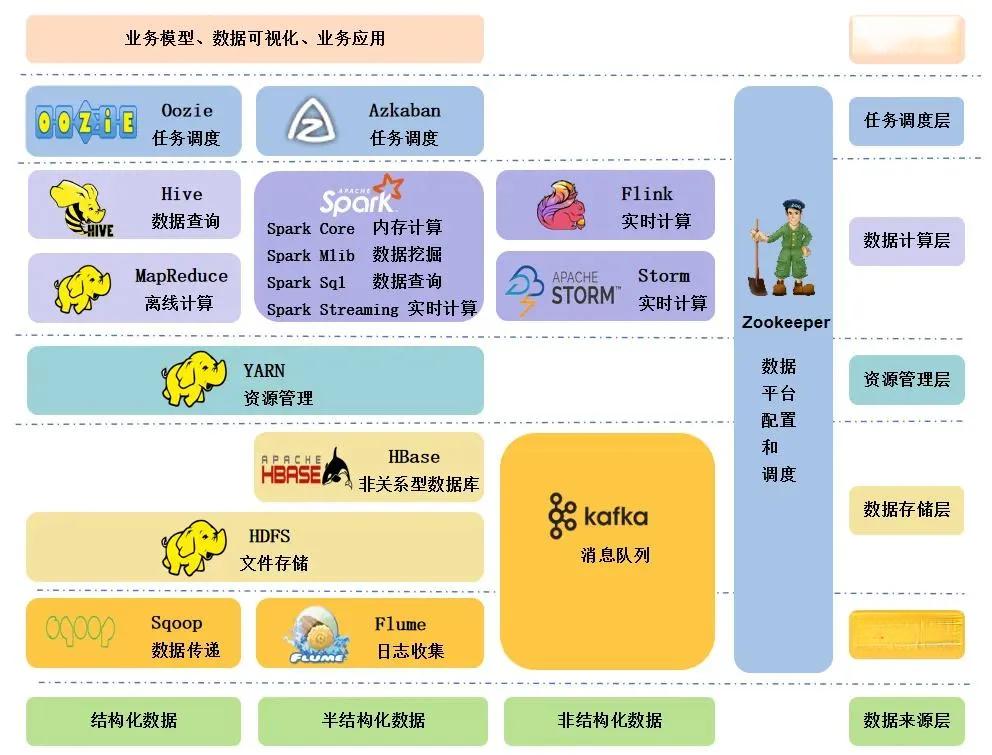
Hadoop:大数据时代的分布式计算引擎
Hadoop是由Apache基金会开发的开源分布式计算框架,旨在为海量数据提供存储和处理能力。它最初受到Google MapReduce和Google File System(GFS)的启发,自2005年推出以来,已成为大数据处理领域的核心技术之一。
Hadoop核心组件解析
Hadoop的核心组件包括:
- HDFS(Hadoop Distributed File System):分布式文件系统,提供高容错性、高吞吐量的数据存储能力。
- MapReduce:分布式计算框架,通过将任务分解为Map和Reduce两个阶段,实现大规模数据的并行处理。
- YARN(Yet Another Resource Negotiator):资源管理和调度系统,负责分配集群资源和调度任务。
这些组件共同构成了Hadoop强大的数据处理能力,使其能够在廉价的硬件集群上实现高效的数据存储和计算。
Hadoop技术优势与局限性
Hadoop的优势主要体现在:
- 高可靠性:通过数据副本机制,即使部分节点失效也不会导致数据丢失。
- 高扩展性:能够方便地扩展到数千个节点,支持PB级数据处理。
- 高效性:通过并行处理,大幅提高数据处理速度。
- 高容错性:自动检测和恢复故障,保证系统稳定运行。
然而,Hadoop也存在一些局限性:
- 不适合低延迟数据访问:Hadoop更适合批量处理,而非实时查询。
- 无法高效存储大量小文件:这会占用过多NameNode内存资源。
- 不支持多用户并发写入和随机修改文件。
Hadoop在各行业的实际应用
尽管存在局限性,Hadoop在多个行业都有广泛的应用:
- 电子商务:eBay利用Hadoop分析用户行为,优化商品推荐和搜索结果。
- 金融服务:Visa使用Hadoop快速分析交易数据,检测可疑交易,将分析时间从一个月缩短到13分钟。
- 能源开采:美国第二大石油公司Chevron使用Hadoop处理海洋地震数据,辅助寻找油矿位置。
- 医疗保健:IBM的Watson系统使用Hadoop集群进行语义分析,帮助医生更好地诊断和治疗患者。
Hadoop未来发展趋势
随着大数据技术的不断发展,Hadoop也在不断演进:
- 实时处理能力提升:通过与Spark等实时计算框架结合,Hadoop正在向实时数据分析领域拓展。
- 生态系统完善:Hadoop生态系统不断丰富,如Hive、Pig等工具简化了数据分析流程。
- 云原生化:越来越多的企业将Hadoop部署在云端,以获得更灵活的资源管理和更便捷的运维。
尽管面临来自Spark等新兴技术的挑战,Hadoop凭借其成熟的技术体系和庞大的用户基础,仍将在大数据处理领域发挥重要作用。未来,Hadoop将继续朝着更高效、更易用、更智能的方向发展,为各行各业的数据处理需求提供强大支持。