Google 发布 CodeGemma 7B,8K上下文,性能超CodeLlama 13B
发布时间:2024-09-16
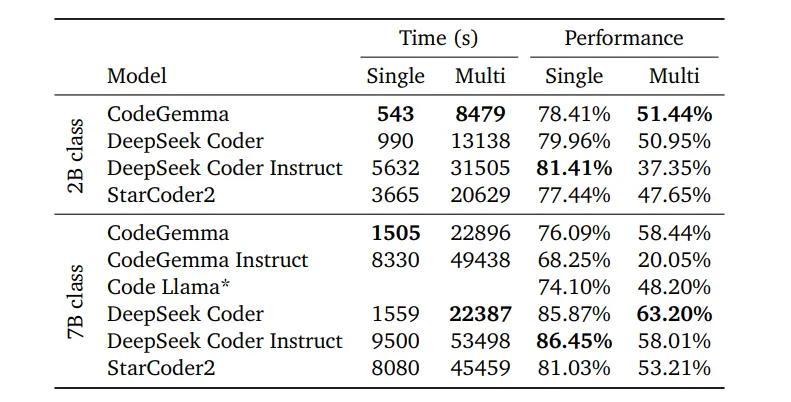
谷歌最新发布的CodeGemma 7B代码生成模型在性能上超越了Meta的CodeLlama 13B,引起了业界广泛关注。这款模型不仅在模型规模上小于CodeLlama 13B,还具备8K的上下文处理能力,展现了“小而强大”的特性。那么,CodeGemma 7B是如何实现这一突破的?它又将为AI技术发展带来哪些启示?
CodeGemma 7B模型性能超越CodeLlama 13B
CodeGemma 7B在多个基准测试中表现出色。在HumanEval等代码基准测试中,它不仅超越了同规模的7B模型,甚至在某些方面可以媲美13B的CodeLlama。这种性能优势主要得益于CodeGemma 7B在多个方面的技术创新。
多文件打包技术提升代码生成能力
CodeGemma 7B采用了多文件打包技术,以提高模型与现实世界应用的对齐度。具体来说,它通过将最相关的源文件放置在代码仓库中,并尽可能将它们分组到相同的训练示例中来创建训练示例。这种技术使得模型能够更好地处理基于存储库级别的上下文生成代码,而不是局限于单个文件。
8K上下文处理能力增强模型推理能力
CodeGemma 7B具备8K的上下文处理能力,这在当前开源代码生成模型中是领先的。这种能力使得模型能够处理更长的代码序列,从而在复杂的代码生成任务中表现出更好的性能。相比之下,CodeLlama 13B的上下文处理能力为4K,这可能是CodeGemma 7B在某些任务中超越CodeLlama 13B的原因之一。
高效训练策略提升模型性能
CodeGemma 7B采用了高效的训练策略,包括使用大规模的训练数据和先进的微调技术。模型在大约5000亿个主要为英语、数学和代码的数据上进行了进一步训练,以提高逻辑和数学推理能力。此外,CodeGemma 7B还采用了基于人类反馈的强化学习(RLHF)技术,进一步提升了模型的性能。
小规模模型或成AI技术新趋势
CodeGemma 7B的成功表明,通过技术创新,小规模模型也可以实现与大规模模型相当甚至更好的性能。这种趋势可能会对未来AI技术的发展产生深远影响。首先,它可能会降低AI模型的开发和部署成本,使得更多企业和个人能够利用AI技术。其次,小规模模型可能更容易在资源受限的设备上运行,从而拓展AI技术的应用场景。最后,这种趋势可能会推动AI模型的架构创新,为AI技术的发展开辟新的方向。
CodeGemma 7B的发布标志着代码生成模型的一个重要里程碑。它不仅展示了谷歌在AI技术方面的实力,也为整个AI行业提供了新的发展方向。随着技术的不断进步,我们有理由期待看到更多像CodeGemma 7B这样“小而强大”的AI模型出现,推动AI技术向更高效、更普及的方向发展。