【机器学习】基于YOLOv10实现你的第一个视觉AI大模型
发布时间:2024-09-18
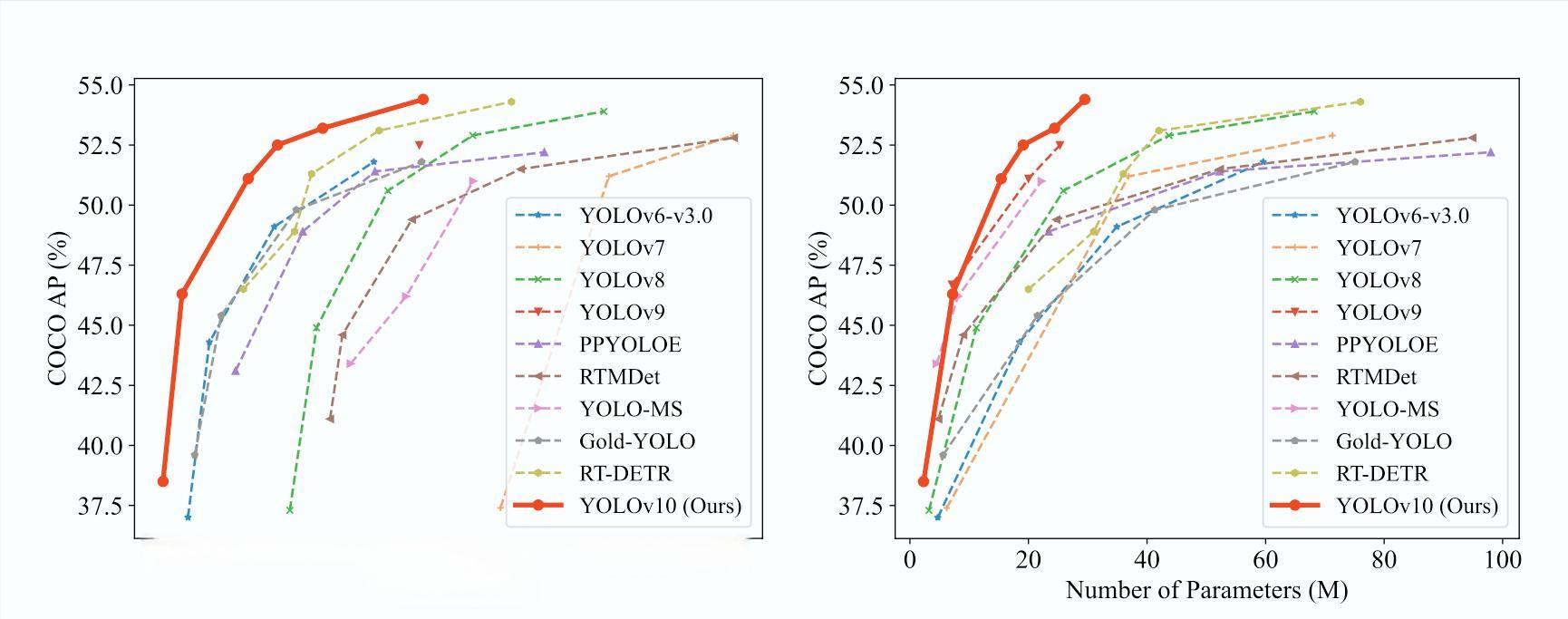
2024年5月23日,清华大学的研究团队发布了YOLO系列的最新版本——YOLOv10。这款实时目标检测模型在性能和效率上都取得了显著突破,为计算机视觉领域带来了新的可能性。
YOLOv10的核心创新在于彻底取消了传统的非极大值抑制(NMS)后处理步骤。NMS虽然能有效减少冗余检测框,但会显著增加推理延迟,并且对模型性能有负面影响。为了解决这个问题,YOLOv10引入了一致的双重分配策略。在训练阶段,模型采用一对多的标签分配方式,为每个真实物体分配多个正样本。而在推理阶段,则采用一对一的分配策略,直接输出最佳预测结果,无需额外的NMS处理。这种设计不仅大大提高了推理速度,还使得YOLOv10能够实现真正的端到端部署。
除了后处理的改进,YOLOv10还采用了整体效率-精度驱动的模型设计策略。研究团队从效率和精度两个角度全面优化了模型的各个组件。例如,他们提出了倒置残差移动块(iRMB)模块,结合了CNN和Transformer架构的优点,既保持了模型的高效性,又增强了特征提取能力。此外,YOLOv10还引入了大核卷积和部分自注意力(PSA)模块,在不增加过多计算成本的情况下进一步提升了模型性能。
这些改进使得YOLOv10在多个方面都超越了前代版本和其他竞争对手。在COCO数据集上,YOLOv10-S在保持相似精度的情况下,比RT-DETR-R18快1.8倍,参数和FLOPs减少了2.8倍。与YOLOv9-C相比,YOLOv10-B在相同性能下的延迟减少了46%,参数减少了25%。这些数据充分证明了YOLOv10在实时目标检测领域的领先地位。
YOLOv10的发布不仅推动了目标检测技术的发展,更重要的是,它使得构建和训练高质量的视觉AI模型变得更加容易。研究团队提供了详细的论文和开源代码,使得即使是AI领域的初学者也能快速上手。这种“开箱即用”的特性大大降低了视觉AI应用的门槛,为各行各业的创新应用打开了大门。
随着YOLOv10的广泛应用,我们可以期待看到更多令人兴奋的视觉AI应用涌现。无论是自动驾驶、安防监控,还是智能家居等领域,都将受益于这种高效、精准的目标检测技术。YOLOv10的出现,无疑将加速我们迈向更加智能、便捷的未来。