Flink技术简介与入门
发布时间:2024-09-18
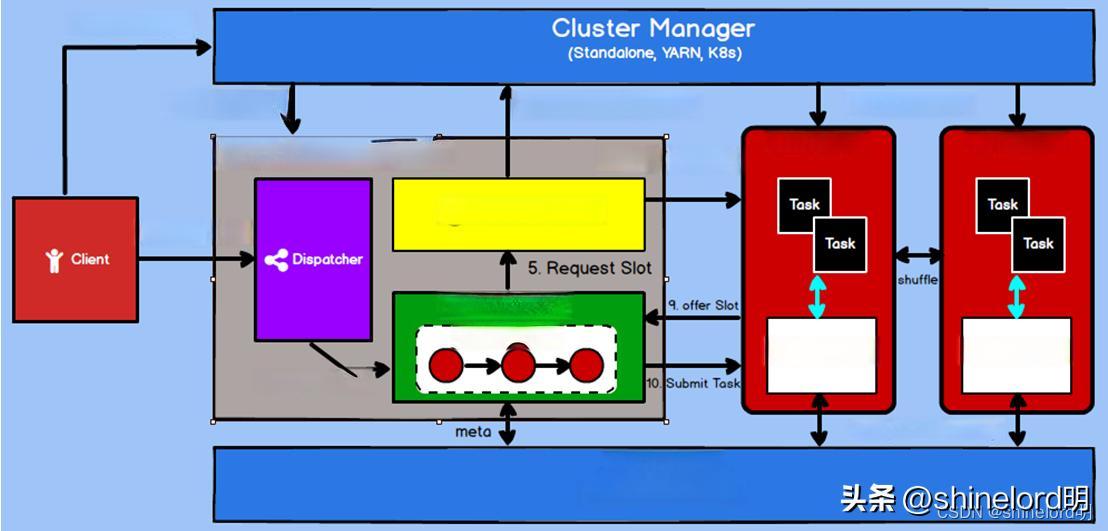
在当今数据驱动的世界中,实时数据处理已成为企业洞察业务动态、快速响应市场变化的关键能力。Apache Flink作为一款先进的流处理框架,正在重塑实时数据处理的格局。Flink以其高吞吐、低延迟和强大的状态管理能力,为企业提供了处理海量实时数据的有力工具。
Flink的核心优势在于其真正的流处理架构。与Spark Streaming的微批处理模型不同,Flink能够实现毫秒级的处理延迟,满足对实时性要求极高的应用场景。例如,在金融交易领域,Flink可以实时分析市场数据,帮助交易员快速做出决策。在物联网场景中,Flink能够实时处理传感器数据,实现设备的智能控制。
Flink的另一个重要特性是对事件时间(Event Time)的支持。在流处理中,数据可能因网络延迟等原因出现乱序到达的情况。Flink通过事件时间语义,能够正确处理这些乱序数据,保证结果的准确性。这种能力使得Flink在处理复杂事件处理(CEP)场景时表现出色,如实时欺诈检测、实时智能推荐等。
状态管理是Flink另一大亮点。Flink提供了强大的状态后端存储系统,如自研的GeminiStateBackend,支持存储计算分离,大幅提升双流或多流Join作业的效率。在Nexmark流计算标准性能测试中,Flink的性能是开源版本的2倍左右。这种高效的状态管理能力,使得Flink能够处理大规模、复杂的状态计算任务。
与传统批处理框架相比,Flink还具有批流一体化的特点。这意味着开发者可以使用相同的API来处理批量数据和实时数据流,大大简化了开发流程。同时,Flink还支持高度灵活的窗口操作,包括基于时间、计数、会话等不同类型窗口,满足各种复杂的数据处理需求。
让我们通过一个简单的入门案例来了解Flink的使用方法。假设我们需要实时统计网站的访问量,可以使用以下Flink SQL语句:
CREATE TABLE clicks (
user_id INT,
url VARCHAR,
timestamp TIMESTAMP(3)
) WITH (
'connector' = 'kafka',
'topic' = 'clicks',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json'
);
CREATE TABLE click_counts (
url VARCHAR,
count BIGINT
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/flink',
'table-name' = 'click_counts'
);
INSERT INTO click_counts
SELECT url, COUNT(*) AS count
FROM clicks
GROUP BY url, TUMBLE(timestamp, INTERVAL '1' MINUTE);
这段代码首先定义了从Kafka主题读取点击数据的表
clicks
,然后创建了一个输出到MySQL数据库的表
click_counts
。最后,使用
INSERT INTO
语句实时统计每分钟每个URL的点击次数,并将结果写入数据库。这个简单的例子展示了Flink处理实时数据流的强大能力。
随着实时数据处理需求的不断增长,Flink的应用场景正在迅速扩展。从实时数据分析到物联网应用,从金融交易到社交媒体,Flink正在成为企业构建实时数据处理平台的首选技术。随着技术的不断演进和社区的蓬勃发展,Flink必将在未来的大数据处理领域发挥更加重要的作用。