多模态大型语言模型 (LLM) 的工作原理
发布时间:2024-09-18
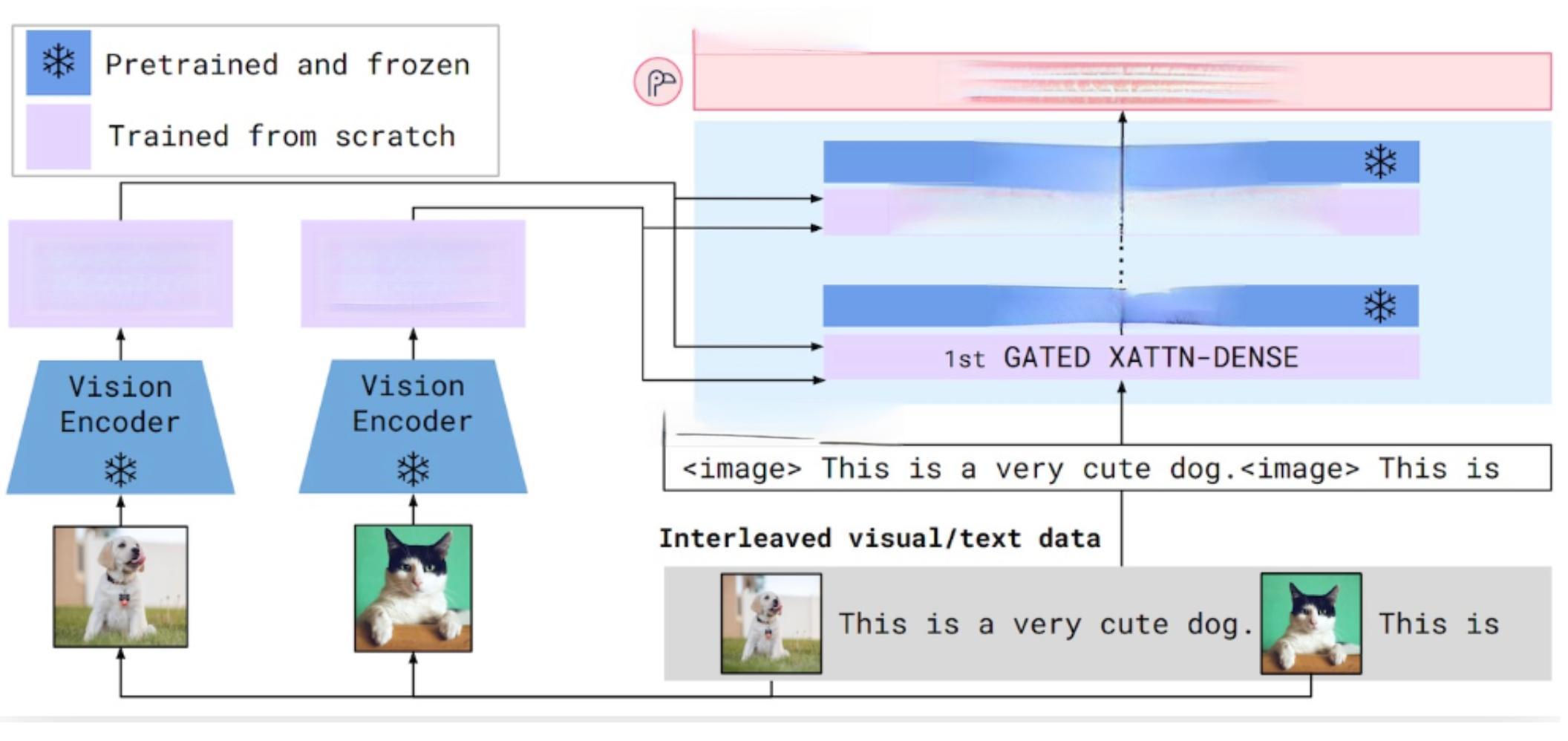
多模态大型语言模型(MLLM)正在引领人工智能领域的新革命。这些模型不仅能处理文本,还能理解和生成图像、音频等多种形式的内容,为人类与AI的交互开辟了新的可能性。
MLLM的核心架构通常包括三个主要模块:模态编码器、连接器和大型语言模型(LLM)。模态编码器负责将原始信息(如图像)编码成特征,连接器则将这些特征处理成LLM易于理解的形式,即视觉Token。LLM作为“大脑”,综合这些信息进行理解和推理,生成回答。以Qwen-VL为例,LLM参数量为7.7B,约占总参数量的80.2%,视觉编码器次之(1.9B,约占19.7%),而连接器参数量仅有0.08B。
训练MLLM是一个复杂的过程,通常包括预训练、指令微调和对齐微调三个阶段。预训练阶段通过大量配对数据将图片信息对齐到LLM的表征空间。指令微调阶段则通过多样化的任务数据提升模型在下游任务上的性能。对齐微调阶段使用强化学习技术使模型对齐人类价值观或某些特定需求。
MLLM的发展带来了令人惊叹的新能力。例如,GPT-4V能够基于图像编写网站代码,理解表情包的深层含义,甚至进行无OCR的数学推理。这些能力远远超出了传统多模态模型的范畴,显示出通向通用人工智能的潜力。
然而,MLLM也面临着诸多挑战。其中最突出的是多模态幻觉问题,即模型生成的回答与图片内容不符。这源于视觉和文本本质上是异构的信息,完全对齐两者具有相当大的挑战。增大图像分辨率和提升训练数据质量是降低多模态幻觉的两种直观方式,但根本解决仍需深入研究多模态幻觉的成因和解法。
将MLLM与人类大脑的多模态信息处理能力进行对比,我们可以发现一些有趣的相似之处。人类大脑同样具有处理多种感官信息的能力,能够将视觉、听觉、触觉等信息整合起来形成对世界的认知。MLLM在某种程度上模仿了这一过程,但目前还远远无法达到人类大脑的灵活性和创造力。
展望未来,MLLM的发展方向可能包括:进一步提升模型的多模态能力,支持更多样化的输入输出形式;探索更高效的训练方法,降低计算成本;以及深入研究多模态幻觉等关键问题。随着技术的进步,我们有理由相信,未来的MLLM将能够更好地理解和生成复杂多样的信息,为人类带来更多惊喜和便利。