学习笔记-模型训练加速
发布时间:2024-09-19
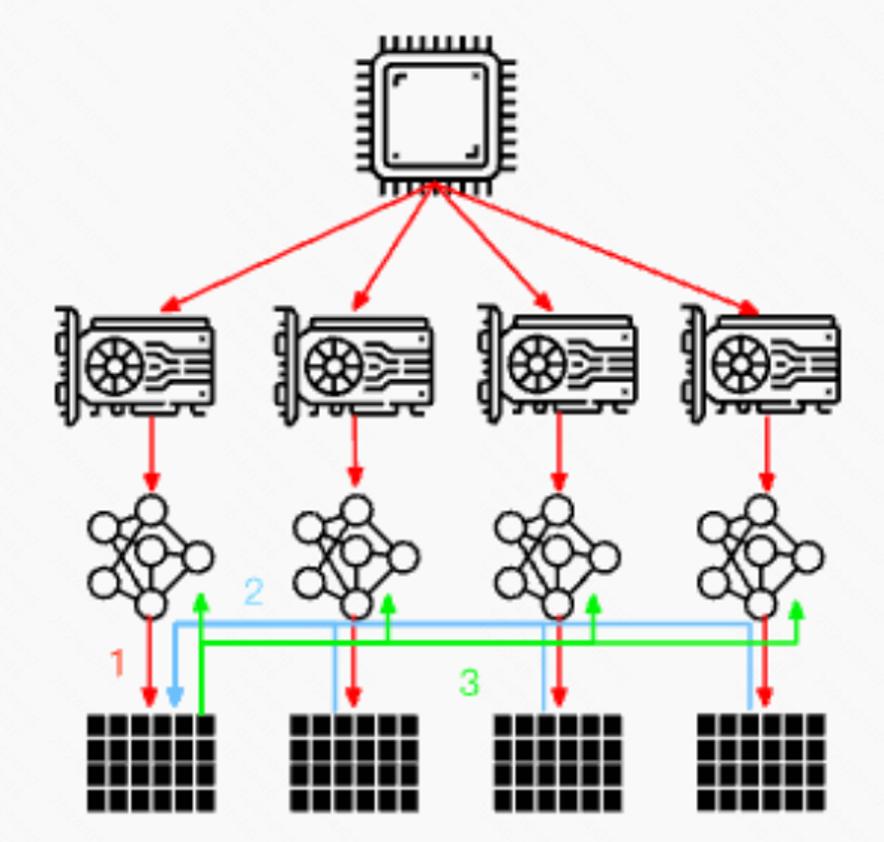
在深度学习领域,随着模型规模的不断扩大和数据量的急剧增加,模型训练速度已成为制约AI应用推广的关键因素。为了应对这一挑战,研究人员和工程师们开发了一系列加速技术,其中分布式训练和硬件加速是最为重要的两个方向。
分布式训练通过多台计算机或多块GPU协同工作,显著提升了模型训练的速度和效率。其基本原理是将巨大的训练任务拆分成多个子任务,每个子任务在独立的计算节点上单独执行。这些计算节点通过网络进行通信,共享模型参数和梯度信息,从而实现模型的同步更新。这种方式有效解决了单机训练中的计算瓶颈和内存限制问题。
在分布式训练中,数据并行是最常见的方法。它将模型的副本分布在不同的计算设备上,每个设备处理不同的数据子集。每次训练迭代后,各设备上的梯度会被汇总并平均,然后同步更新模型参数。相比之下,模型并行则是将整个神经网络模型拆解分布到不同的计算设备中,不同的设备负责计算网络模型中的不同部分。这种方式适用于模型参数巨大、单机无法容纳整个模型的情况。
为了进一步提高分布式训练的效率,研究者们提出了多种优化策略。参数服务器架构是一种常见的优化策略,它将模型参数的存储和更新与计算梯度的任务分离,有效减少了通信开销和提高了计算效率。异步优化算法允许每个训练节点独立计算梯度并更新模型参数,无需等待其他节点的计算结果,提高了计算效率。高效的通信协议,如AllReduce算法,通过节点间的环形通信,实现了梯度的快速汇总和平均,显著提高了分布式训练的效率。
在硬件加速方面,GPU和TPU是目前最常用的两种加速器。GPU最初设计用于图形渲染,但其强大的并行处理能力使其成为深度学习的理想选择。现代GPU拥有成百上千的核心,可以在同一时刻处理数以千计的小任务。相比之下,TPU是Google为机器学习任务专门设计的硬件加速器,它针对深度学习工作负载进行了深度优化,在执行特定的机器学习算法时能展现出更高的效率。
以BERT模型为例,在NVIDIA V100 GPU上需要3.8毫秒,而在TPU v3上仅需1.7毫秒。在训练ResNet-50模型时,NVIDIA Tesla V100 GPU需要约40分钟,而Google Cloud TPU v3只需15分钟。这些数据充分展示了TPU在深度学习任务上的性能优势。
除了分布式训练和硬件加速,混合精度训练是近年来出现的一种新型加速技术。它通过在深度学习训练过程中同时使用16位浮点数(FP16)和32位浮点数(FP32),显著提高了训练速度并减少了内存占用。使用FP16进行计算可以提高训练速度,因为FP16数据占用的内存带宽只有FP32的一半,现代GPU(如NVIDIA的Tensor Cores)针对FP16运算进行了优化,能够在同一时钟周期内进行更多的FP16操作。
混合精度训练不仅提高了训练速度,还减少了内存占用。FP16数据占用的显存空间只有FP32的一半,因此使用FP16可以显著减少显存占用,使得能够训练更大的模型或使用更大的批量大小。同时,混合精度训练在保持计算精度的同时,提高了计算效率和减少了内存占用。通常,在前向和反向传播过程中使用FP16,而在累积梯度和更新模型参数时使用FP32,以保证数值稳定性和精度。
这些加速技术的出现,极大地推动了AI的发展。它们不仅提高了模型训练的速度,还降低了计算资源消耗,使得研究人员和开发人员能够更快地开发和优化深度学习模型。随着硬件技术的不断进步和算法的持续优化,我们有理由相信,未来的AI模型训练将会变得更加高效和经济。