SambaNova 芯片:深入解析其架构和高性能秘诀
发布时间:2024-09-19
SambaNova Systems推出的SN40L芯片凭借其创新的可重构数据流架构和三层内存系统,在AI加速领域掀起了一场技术革命。这款采用台积电5nm工艺制造的芯片,不仅在性能上超越了传统GPU,更为AI模型的高效运行开辟了新的可能性。
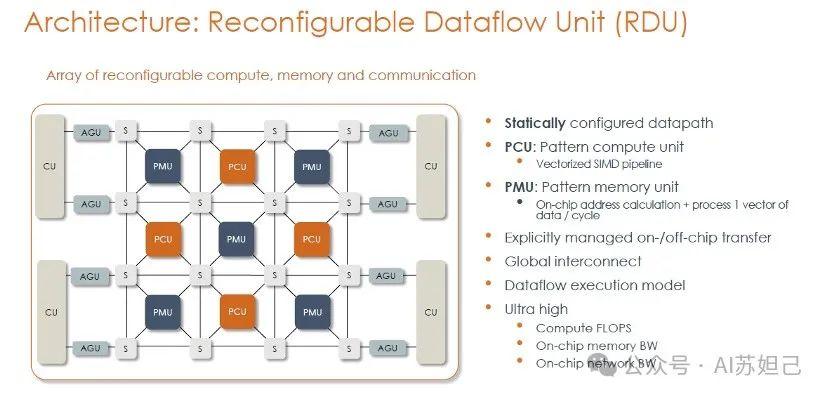
SN40L芯片的核心在于其独特的可重构数据流架构。与传统GPU由大量CUDA核心组成的架构不同,SN40L采用了大量计算单元(PCU)、存储单元(PMU)和通信交换单元(SCU)的阵列排列。这种设计允许芯片根据不同的AI模型需求,动态调整内部数据通路,实现高效的计算和数据流动。
在SN40L中,计算单元PCU集成了矢量化单指令多数据(SIMD)流水线,专门用于高效的矩阵/向量计算。存储单元PMU则是片上SRAM存储器,每个周期可存取一个数据向量,为计算单元提供流畅的数据供应。通信交换单元SCU负责在整个芯片范围内互连各个单元,构建一个可重配的全局互连网络,支持灵活的数据流传输。
这种灵活的架构设计使得SN40L能够针对特定的AI模型,自动生成最优的计算指令和分布式执行策略。SambaNova的编译器技术栈能够分析模型结构特征,并结合硬件资源,自动探索并确定出高度优化的操作映射方案。这种快速的数据流编译技术突破了传统架构的性能瓶颈,实现了卓越的AI加速性能。
然而,仅仅依靠计算架构的创新还不足以应对现代AI模型对内存的巨大需求。SN40L引入了一种创新的三层内存系统,包括片上分布式SRAM、封装内HBM和封装外DDR DRAM。这种设计充分利用了不同层级内存的特点,为AI模型提供了高效的数据访问。
在SN40L中,520 MiB的片上PMU SRAM提供了极高的访问速度,而64 GiB的同封装HBM则提供了更大的容量和更高的带宽。高达1.5 TiB的DDR DRAM则为模型提供了海量的存储空间。这种分层的内存架构不仅能够满足不同规模AI模型的需求,还能通过层次化的数据管理策略,最大化内存系统的整体性能。
SambaNova的创新不仅仅停留在硬件层面。他们还开发了Samba-CoE系统,这是一种由多个小型专家模型组成的组合,每个模型的参数都少几个数量级,但可以达到或超过单片大语言模型的能力。这种模块化方法降低了训练和服务的成本和复杂性,同时也为AI模型的部署提供了更大的灵活性。
在实际应用中,SN40L在处理专家组合(CoE)时展现出了卓越的性能。在8个RDU插槽上运行的各种基准测试中,SN40L展示了从2倍到13倍的加速。对于CoE推理部署,8-插槽RDU节点可将机器占用空间减少多达19倍,将模型切换时间加快15倍至31倍,并且与DGX H100相比实现3.7倍的总体加速,与DGX A100相比实现6.6倍的总体加速。
SambaNova的创新不仅体现在技术层面,更在于他们对AI计算未来趋势的深刻洞察。随着AI模型的规模和复杂度不断增长,传统的计算-内存架构已经难以满足需求。SambaNova通过可重构数据流架构和创新的内存系统,为突破AI计算的内存壁垒提供了新的解决方案。
随着AI技术的快速发展,像SambaNova这样的创新公司正在重新定义AI计算的未来。他们的技术不仅能够应对当前AI模型的挑战,更为未来更复杂、更智能的AI系统铺平了道路。在这个AI驱动的新时代,SambaNova的创新无疑将在推动科技进步和产业变革中发挥重要作用。