SparkSQL溯源工具:验证结果数据准确性的方法
发布时间:2024-09-18
在大数据处理领域,确保结果数据的准确性是一项极具挑战性的任务。传统的数据验证方法往往耗时耗力,尤其是在面对复杂的数据处理逻辑时。然而,随着SparkSQL溯源工具的出现,这一局面正在发生改变。
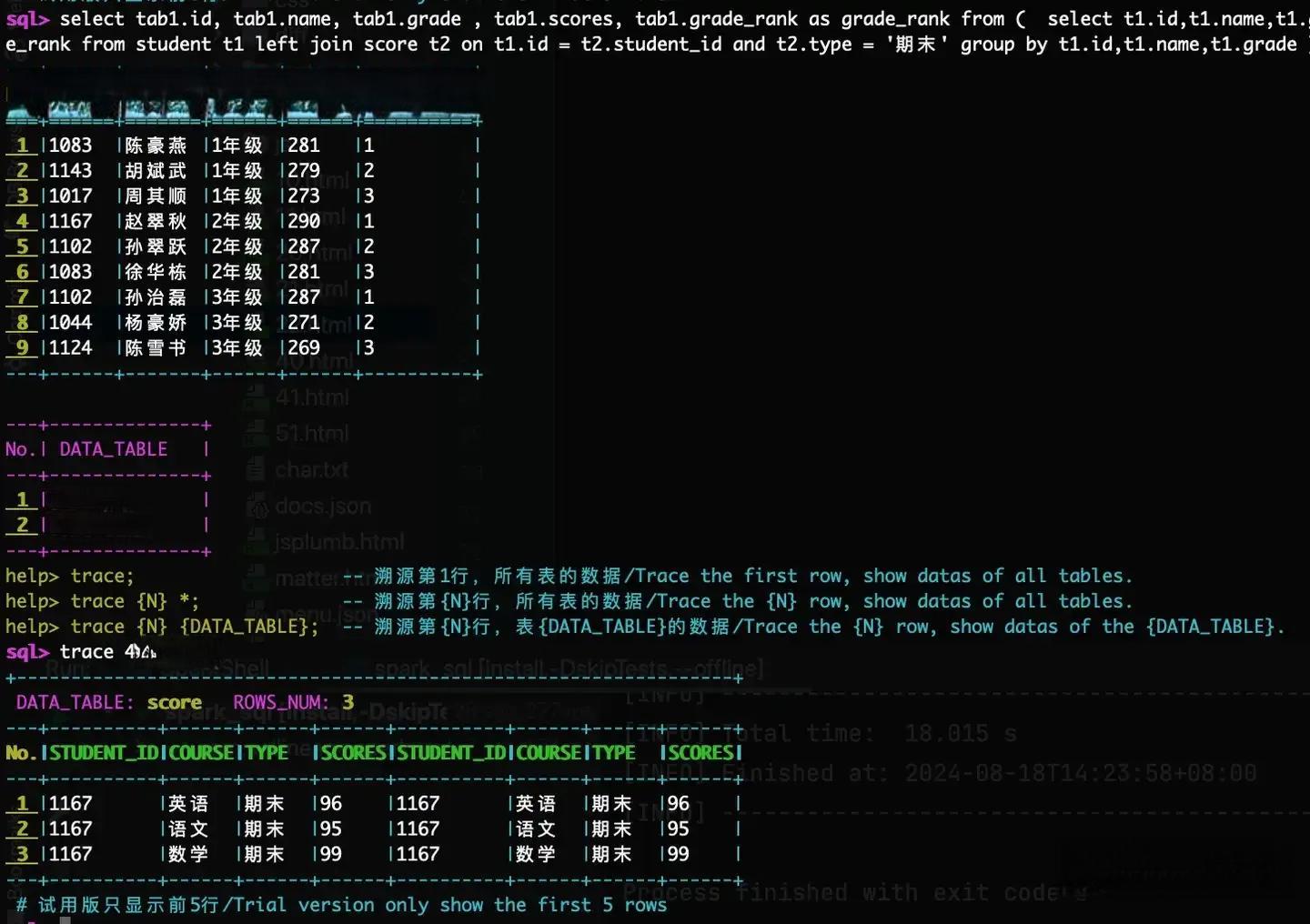
SparkSQL溯源工具的核心功能是能够追踪Spark SQL执行结果,找出每一行数据的源头。这听起来简单,但实际上蕴含着巨大的潜力。想象一下,当你面对一个复杂的SQL查询结果时,能够轻松地追溯每一行数据的来源,这无疑为数据验证工作带来了革命性的变化。
让我们以一个具体的例子来说明SparkSQL溯源工具的工作原理。假设我们有一个SQL查询,用于找出每个年级总分前3名的学生:
select tab1.id, tab1.name, tab1.grade , tab1.scores, tab1.grade_rank as grade_rank from (
select t1.id,t1.name,t1.grade, sum(t2.scores) as scores,
( row_number() over (partition by t1.grade order by sum(t2.scores) desc) ) as grade_rank
from student t1 left join score t2 on t1.id = t2.student_id and t2.type = '期末'
group by t1.id,t1.name,t1.grade
) tab1 where tab1.grade_rank <= 3
这个查询涉及子查询、窗口函数和聚合函数等复杂操作。如果没有SparkSQL溯源工具,要验证结果的准确性可能需要花费大量时间和精力。但是,有了这个工具,我们可以通过简单的命令来查看指定结果数据行的原始数据。这不仅大大简化了验证过程,还提高了验证的准确性。
SparkSQL溯源工具的优势不仅体现在其强大的追踪能力上,还在于它能够应对传统方法难以处理的复杂情况。例如,当原始数据没有主键,或者结果数据被脱敏加密时,传统的验证方法往往无能为力。而SparkSQL溯源工具则能够通过其独特的算法和数据结构,有效地解决这些问题。
然而,要充分发挥SparkSQL溯源工具的潜力,还需要注意一些关键点:
-
确保数据处理逻辑的准确性。虽然溯源工具可以帮助我们验证结果,但前提是处理逻辑本身是正确的。
-
保证原始数据的准确性和一致性。溯源工具只能追溯数据的来源,无法保证原始数据本身的准确性。
-
合理使用工具。虽然SparkSQL溯源工具功能强大,但并不意味着它可以完全取代人工验证。在某些情况下,结合人工分析可能会得到更好的验证效果。
总的来说,SparkSQL溯源工具为大数据处理领域提供了一个强有力的工具,极大地简化了结果数据准确性的验证过程。它不仅提高了验证的效率,还为数据质量问题的快速定位和解决提供了可能。随着大数据应用的日益广泛,SparkSQL溯源工具无疑将在数据质量保障方面发挥越来越重要的作用。